SANSA 0.7.1 (Semantic Analytics Stack) Released
We are happy to announce SANSA 0.7.1 – the seventh release of the Scalable Semantic Analytics Stack. SANSA employs distributed computing via Apache Spark and Flink in order to allow scalable machine learning, inference and querying capabilities for large knowledge graphs.
- Website: http://sansa-stack.net
- GitHub: https://github.com/SANSA-Stack
- Download: http://sansa-stack.net/downloads-usage/
- ChangeLog: https://github.com/SANSA-Stack/SANSA-Stack/releases
You can find usage guidelines and examples at http://sansa-stack.net/user-guide.
The following features are currently supported by SANSA:
- Reading and writing RDF files in N-Triples, Turtle, RDF/XML, N-Quad, TRIX format
- Reading OWL files in various standard formats
- Query heterogeneous sources (Data Lake) using SPARQL – CSV, Parquet, MongoDB, Cassandra, JDBC (MySQL, SQL Server, etc.) are supported
- Support for multiple data partitioning techniques
- SPARQL querying via Sparqlify and Ontop and Tensors
- Graph-parallel querying of RDF using SPARQL (1.0) via GraphX traversals (experimental)
- RDFS, RDFS Simple and OWL-Horst forward chaining inference
- RDF graph clustering with different algorithms
- Terminological decision trees (experimental)
- Knowledge graph embedding approaches: TransE (beta), DistMult (beta)
Noteworthy changes or updates since the previous release are:
- TRIX support
- A new query engine over compressed RDF data
- OWL/XML Support
Deployment and getting started:
- There are template projects for SBT and Maven for Apache Spark as well as for Apache Flink available to get started.
- The SANSA jar files are in Maven Central i.e. in most IDEs you can just search for “sansa” to include the dependencies in Maven projects.
- Example code is available for various tasks.
- We provide interactive notebooks for running and testing code via Docker.
We want to thank everyone who helped to create this release, in particular the projects Big Data Ocean, SLIPO, QROWD, BETTER, BOOST, MLwin, PLATOON and Simple-ML. Also check out our recent articles in which we describe how to use SANSA for tensor based querying, scalable RDB2RDF query execution, quality assessment and semantic partitioning.
Spread the word by retweeting our release announcement on Twitter. For more updates, please view our Twitter feed and consider following us.
Greetings from the SANSA Development Team
Squerall to SANSA-DataLake
Generally, implementing an OBDA architecture atop Big Data raises three challenges:
- Query translation. SPARQL queries must be translated into the query language of each of the respective data sources. A generic and dynamic translation between data models is challenging (even impossible in some cases e.g., join operations are unsupported in Cassandra and MongoDB).
- Federated Query Execution. In Big Data scenarios it is common to have non-selective queries with large intermediate results, so joining or aggregation cannot be performed on a single node, but only distributed across a cluster.
- Data silos. Data coming from various sources can be connected to generate new insights, but it may not be readily ‘joinable’ (cf. definition below).
To target the aforementioned challenges we have built Squerall, an extensible framework for querying Data Lakes.
- It allows ad hoc querying of large and heterogeneous data sources virtually without any data transformation or materialization.
- It allows the distributed query execution, in particular the joining of disparate heterogeneous sources.
- It enables users to declare query-time transformations for altering join keys and thus making data joinable.
- Squerall integrates the state-of-the-art Big Data engines Apache Spark and Presto with the semantic technologies RML and FnO.
System Overview
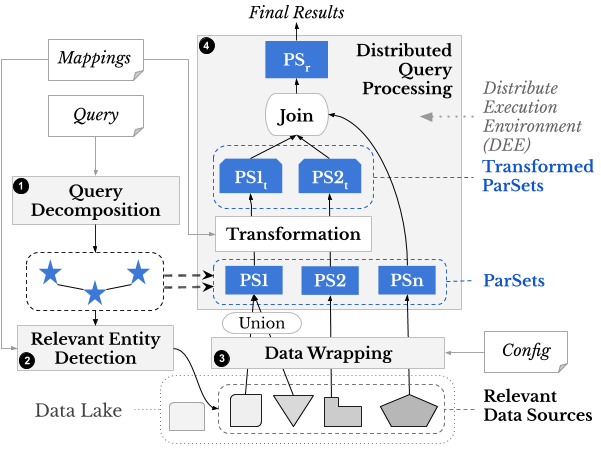
Squerall General Architecture
Squerall consists of four main components (see numbered boxes in the figure above). Because of Squerall extensible design, also for clarity, we here use the generic ParSets and DEE concepts instead of Squerall’s underlying equivalent concrete terms, which differ from engine to engine. ParSet, from Parallel dataSet, is a data structure that can be distributed and operated on in parallel; it follows certain data model, like tables in tabular databases, graph in graph databases, or a document in a document database. DEE, from Distributed Execution Environment, is the shared physical space where ParSets can be transformed, aggregated and joined together.
The architecture accepts three user inputs (refer to Squerall Basics for more details):
- Mappings: it contains association between data source entities and attributes (eg table and column in a tabular database or collection and document in a document database) to ontology properties and classes.
- Config: it contains the access information needed to connect to the heterogeneous data sources, e.g., username, password, or cluster setting, e.g., hosts, ports, cluster name, etc.
- Query: a query in SPARQL query language.
The fours components of the architecture are described as follows:
(1) Query Decomposor. This component is commonly found in OBDA and query federation systems. It decomposes the query’s Basic Graph Pattern (BGP, conjunctive set of triple patterns in the where clause) into a set of star-shaped sub-BGPs, where each sub-BGP contains all the triple patterns sharing the same subject variable. We refer to these sub-BGPs as stars for brevity; (see below figure left, stars are shown in distinct colored boxes).
(2) Relevant Entity Extractor. For every extracted star, this component looks in the Mappings for entities that have attributes mappings to each of the properties of the star. Such entities are relevant to the star.
(3) Data Wrapper. In the classical OBDA, SPARQL query has to be translated to the query language of the relevant data sources. This is in practice hard to achieve in the highly heterogeneous Data Lake settings. Therefore, numerous recent publications advocated for the use of an intermediate query language. In our case, the intermediate query language is DEE’s query language, dictated by its internal data structure. The Data Wrapper generates data in POA’s data structure at query-time, which allows for the parallel execution of expensive operations, e.g., join. There must exist wrappers to convert data entities from the source to DEE’s data structure, either fully, or partially if parts of the data can be pushed down to the original source. Each identified star from step (1) will generate exactly one ParSet. If more than an entity are relevant, the ParSet is formed as a union. An auxiliary user input Config is used to guide the conversion process, e.g., authentication, or deployment specifications.
(4) Distributed Query Processor. Finally, ParSets are joined together forming the final results. ParSets in the DEE can undergo any query operation, e.g., selection, aggregation, ordering, etc. However, since our focus is on querying multiple data sources, the emphasis is on the join operation. Joins between stars translate into joins between ParSets (figure below phase I). Next, ParSet pairs are all iteratively joined to form the Results ParSet (figure below phase II) . In short, extracted join pairs are initially stored in an array. After the first pair is joined, it iterates through each remaining pair to attempt further joins or, else, add to a queue . Next, the queue is similarly iterated, when a pair is joined, it is unqueued. The algorithm completes when the queue is empty. As the Results ParSet is a ParSet, it can also undergo query operations. The join capability of ParSets in the DEE replaces the lack of the join common in many NoSQL databases, e.g., Cassandra, MongoDB. Sometimes ParSets cannot be readily joined due to a syntactic mismatch between attribute values. Squerall allows users to declare Transformations, which are atomic operations applied to textual or numeral values.
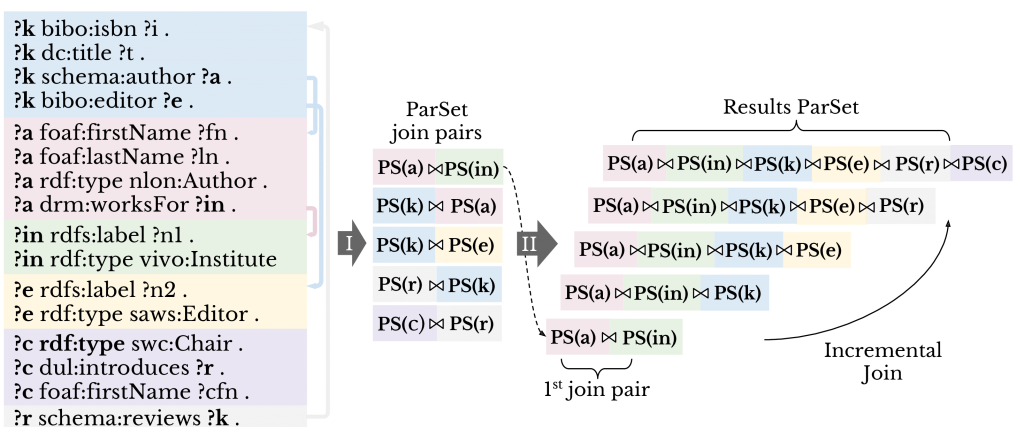
From query to ParSets to joins between ParSets
Squerall has two query engine implementations using Apache Spark and Presto. For Spark, ParSets are represented by DataFrames and joins between ParSets are translated into joins between DataFrames. Presto accepts only SQL queries, so ParSets are represented by SQL SELECT sub-queries, and joins between ParSets are represented by join between SELECT sub-queries. Similarly, operations on ParSets derived from the SPARQL query are translated into equivalent SQL functions in Spark and SQL operations in Presto.
Evaluation
We evaluate Squerall performance when using Berlin Benchmark (BSBM) with three scales (0,5M, 1,5M, 5M products), nine adapted queries and five data sources (Cassandra, MongoDB, Parquet, CSV, MySQL) populated from BSBM generated data. The experiments were run in a cluster of three machines each having DELL PowerEdge R815, 2x AMD Opteron 6376 (16 cores) CPU and 256GB RAM.
We compare the query execution time between Spark-based Squerall vs Presto-based Squerall. The results, shown in the below figure suggest that Presto-based Squerall is faster in the majority of queries than Spark-based Squerall.
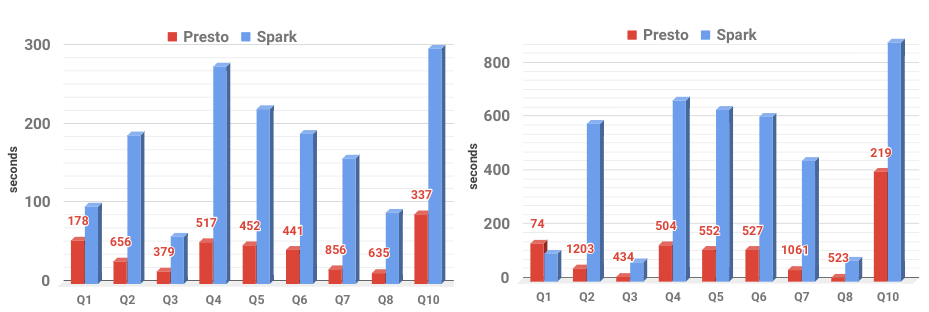
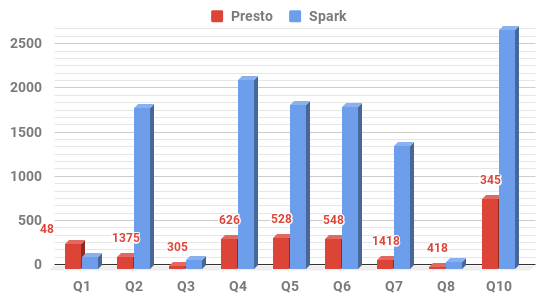
Figure: Query Execution Time of the three scales, 0,5M top left, 1,5M top right and 5M bottom. The numbers on top of Presto bars show percentage of Spark’s execution time to Presto’s, e.g., 178 means that Presto is 178% faster than Spark.
We also record the time taken by the sub-phases of the query execution. Results suggest that Query Analysis and Relevant Source Detection phases have a minimum contribution to the overall query execution process, and that the actual Query Execution by Spark/Presto is what dominates the process.
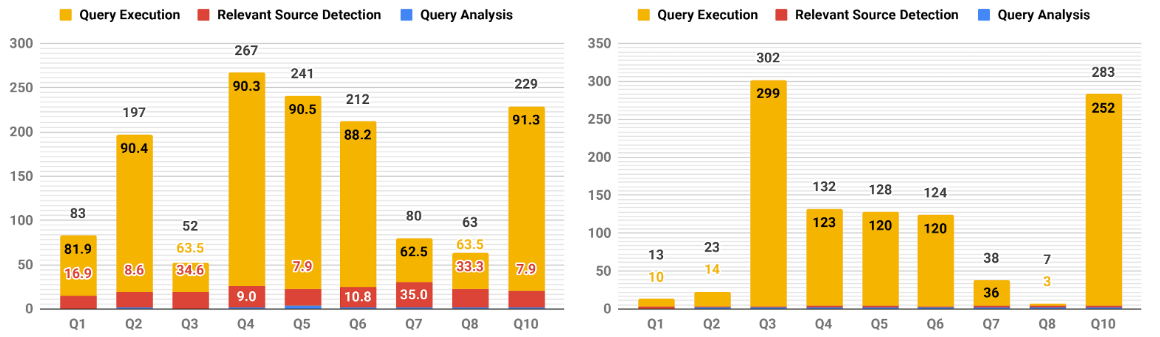
Query Execution Time breakdown into its sub-phases: Query Analysis, Relevant Source Detection and Query Execution.
In order to evaluate the ratio between query execution and data size scales, we plot the query execution times of the three scales into one graph.
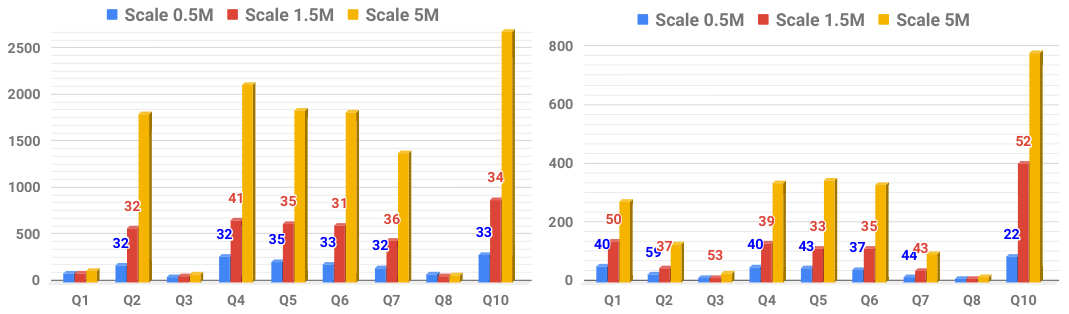
Scalability of Query Execution Time versus Data Size. Spark-based Squerall in the left and Presto-based in the right.
Integration into SANSA and Usage
Spark-based Squerall has been integrated into SANSA Stack with a separate layer called SANSA-DataLake callable from the SANSA-Query layer, where it had so far three releases. See full details in its dedicated page.
Below is an example of how Squerall, SANSA-DataLake after the integration, can be triggered from inside SANSA-Query:
|
1 2 3 4 5 6 7 |
import net.sansa_stack.query.spark.query._ val configFile = "/config" val mappingsFile = "/mappings.ttl" val query = "SPARQL query" val resultsDF = spark.sparqlDL(query, mappingsFile, configFile) |
Input: configFile is the path to the config file (example), mappingsFile is the path to the mappings file (example) and query is a string variable holding a correct SPARQL query (example).
Output: resultsDF is a Spark DataFrame with the columns corresponding to the SELECTed variables in the SPARQL query.
Publications
For further reading and full details, we refer readers to the following publications:
Quality Assessment of RDF Datasets at Scale
“Data is the new oil. It’s valuable, but if unrefined it cannot really be used. It has to be changed into gas, plastic, chemicals, etc to create a valuable entity that drives profitable activity; so must data be broken down, analyzed for it to have value.”
— Clive Humby (UK Mathematician and Chief Data Scientist at Starcount)
Extracting meaningful information from data which is considered being chaos has been a challenge for many years now. Often, this data is coming in an unstructured form and is increasing daily, there is a challenge to analyze and use such data. Data quality issues (when dealing with such amount of data) becomes a challenge in the data world. Such unstructured data acquired from different sources often causes a delay in deriving insights and analysis due to data quality issues.
In order to handle this ambiguity and complexity of data is modeling using the Semantic Web Technologies. Over the last years, Linked Data has grown continuously. Today, we count more than 10,000 datasets being available online following Linked Data standards. These standards allow data to be machine-readable and interoperable. Nevertheless, many applications, such as data integration, search, and interlinking, cannot take full advantage of Linked Data if it is of low quality. There exist a few approaches for the quality assessment of Linked Data, but their performance degrades with the increase in data size and quickly grows beyond the capabilities of a single machine.
In order to overcome this, we present DistQualityAssessment [1] — an open-source implementation of quality assessment of large RDF datasets (integrated into SANSA) that can scale out to a cluster of machines.
Getting Started
Within the scope of this post, we will be using SANSA-Notebooks as a base setup for running SANSA and in particular distributed quality assessment. You can also run it using your prefered IDE (see here for more details on how to setup SANSA on IDE).
SANSA Notebooks (or SANSA Workbench) is an interactive Spark Notebooks for running SANSA-Examples and are easy to deploy with docker-compose. Deployment stack includes Hadoop for HDFS, Spark for running SANSA examples, Hue for navigation and copying file to HDFS. The notebooks are created and run using Apache Zeppelin. The setup requires that you have “Docker Engine >= 1.13.0, docker-compose >= 1.10.0, and around 10 GB of disk space for Docker images”.
After you are done with the docker installation, clone the SANSA-Notebooks git repository:
|
1 2 |
git clone https://github.com/SANSA-Stack/SANSA-Notebooks cd SANSA-Notebooks |
Get the SANSA Examples jar file (requires wget):
|
1 |
make |
Start the cluster (this will lead to downloading BDE docker images):
|
1 |
make up |
When start-up is done you will be able to access the SANSA notebooks.
To load the data to your cluster simply do:
|
1 |
make load-data |
After you load the data (you can upload your own data using Hue – HDFS File Browser or simply adding them to the folder and run the command above to lead the data), go on and open SANSA Notebooks, choose any available notebooks or create a new one (choose Spark as Interpreter) and add the following code snippets:
|
1 2 3 4 5 6 7 |
import org.apache.jena.riot.Lang import net.sansa_stack.rdf.spark.io._ import net.sansa_stack.rdf.spark.qualityassessment._ val input = "hdfs://namenode:8020/data/rdf.nt" val lang = Lang.NTRIPLES val triples = spark.rdf(lang)(input) |
In order to read data in an efficient and scalable way, SANSA has its own readers for reading different RDF serialization formats. In our case, we are going to use NTRIPLES (see Line 5). For that reason, we have to import io API (see Line 2) in order to use such io operations.
As the data is kept in HDFS, we will have to specify the path where data is standing (see Line 5) and the syntax they are represented (in our case we are using NTRIPLES, see Line 6). Afterword, we generate Spark RDD (Resilient Distributed Datasets) representations of Triples (see Line 7) which allows us to perform a quality assessment at scale.
The SANSA quality assessment component is part of the framework and therefore the call can be done easily by just using the qualityassessment namespace (see Line 3). It comes with different quality assessment metrics which can be easily used. Below, we list part of that list:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
// compute quality assessment val completeness_schema = triples.assessSchemaCompleteness() val completeness_interlinking = triples.assessInterlinkingCompleteness() val completeness_property = triples.assessPropertyCompleteness() val syntacticvalidity_literalnumeric = triples.assessLiteralNumericRangeChecker() val syntacticvalidity_XSDDatatypeCompatibleLiterals = triples.assessXSDDatatypeCompatibleLiterals() val availability_DereferenceableUris = triples.assessDereferenceableUris() val relevancy_CoverageDetail = triples.assessCoverageDetail() val relevancy_CoverageScope = triples.assessCoverageScope() val relevancy_AmountOfTriples = triples.assessAmountOfTriples() val performance_NoHashURIs = triples.assessNoHashUris() val understandability_LabeledResources = triples.assessLabeledResources() |
The quality assessment metric evaluation generate a numerical representation of the quality check. Here, for example we want to assess the Schema Completeness (see Quality Assessment for Linked Open Data: A Survey paper for more details on the metric definitions) on a given dataset. We can assess it by just running:
|
1 |
val completeness_schema = triples.assessSchemaCompleteness() |
Within the SANSA Notebooks, we can visualize the metric values and export the results if needed for further analysis.

For more details about the architecture, technical details of the approach and its evaluation/comparison with other systems, please check out our paper [1].
After you are done, you can stop the whole stack:
|
1 |
make down |
That’s it, hope you enjoyed it. If you have any question or suggestion, or you are planning a project with SANSA, perhaps by using this quality assessment? We would love to hear about it! b.t.w we always welcome new contributors to the project! Please see our contribution guide for more details on how to get started contributing to SANSA.
References
[1]. In Proceedings of 18th International Semantic Web Conference, 2019.
|
1 2 3 4 5 6 7 8 9 |
@InProceedings{sejdiu-2019-sansa-dist-quality-assessment-iswc, Title = {A {S}calable {F}ramework for {Q}uality {A}ssessment of {RDF} {D}atasets}, Author = {Gezim Sejdiu and Anisa Rula and Jens Lehmann and Hajira Jabeen}, Booktitle = {Proceedings of 18th International Semantic Web Conference}, Year = {2019}, Keywords = {2019 sansa sejdiu rula jabeen lehmann group_sda}, Url = {http://jens-lehmann.org/files/2019/iswc_dist_quality_assessment.pdf}, UrlSlides = {https://www.slideshare.net/GezimSejdiu/a-scalable-framework-for-quality-assessment-of-rdf-datasets-iswc-2019-talk} } |
SANSA 0.6 (Semantic Analytics Stack) Released
We are happy to announce SANSA 0.6 – the sixth release of the Scalable Semantic Analytics Stack. SANSA employs distributed computing via Apache Spark and Flink in order to allow scalable machine learning, inference and querying capabilities for large knowledge graphs.
- Website: http://sansa-stack.net
- GitHub: https://github.com/SANSA-Stack
- Download: http://sansa-stack.net/downloads-usage/
- ChangeLog: https://github.com/SANSA-Stack/SANSA-Stack/releases
You can find the FAQ and usage examples at http://sansa-stack.net/faq/.
The following features are currently supported by SANSA:Reading and writing RDF files in N-Triples, Turtle, RDF/XML, N-Quad format
- Reading OWL files in various standard formats
- Query heterogeneous sources (Data Lake) using SPARQL – CSV, Parquet, MongoDB, Cassandra, JDBC (MySQL, SQL Server, etc.) are supported
- Support for multiple data partitioning techniques
- SPARQL querying via Sparqlify and Ontop and Tensors
- Graph-parallel querying of RDF using SPARQL (1.0) via GraphX traversals (experimental)
- RDFS, RDFS Simple and OWL-Horst forward chaining inference
- RDF graph clustering with different algorithms
- Terminological decision trees (experimental)
- Knowledge graph embedding approaches: TransE (beta), DistMult (beta)
Noteworthy changes or updates since the previous release are:
- Tensor representation of RDF added
- Ontop RDB2RDF engine support has been added
- Tensor based querying engine introduced
- RDF data quality assessment methods have been added
- Dataset statistics calculation has been substantially improved
- New clustering algorithms have been added and the interface for clustering has been unified
Deployment and getting started:
- There are template projects for SBT and Maven for Apache Spark as well as for Apache Flink available to get started.
- The SANSA jar files are in Maven Central i.e. in most IDEs you can just search for “sansa” to include the dependencies in Maven projects.
- Example code is available for various tasks.
- We provide interactive notebooks for running and testing code via Docker.
We want to thank everyone who helped to create this release, in particular the projects HOBBIT, Big Data Ocean, SLIPO, QROWD, BETTER, BOOST, MLwin and Simple-ML.
Spread the word by retweeting our release announcement on Twitter. For more updates, please view our Twitter feed and consider following us.
Greetings from the SANSA Development Team
SANSA 0.5 (Semantic Analytics Stack) Released
We are happy to announce SANSA 0.5 – the fifth release of the Scalable Semantic Analytics Stack. SANSA employs distributed computing via Apache Spark and Flink in order to allow scalable machine learning, inference and querying capabilities for large knowledge graphs.
- Website: http://sansa-stack.net
- GitHub: https://github.com/SANSA-Stack
- Download: http://sansa-stack.net/downloads-usage/
- ChangeLog: https://github.com/SANSA-Stack/SANSA-Stack/releases
You can find the FAQ and usage examples at http://sansa-stack.net/faq/.
The following features are currently supported by SANSA:
- Reading and writing RDF files in N-Triples, Turtle, RDF/XML, N-Quad format
- Reading OWL files in various standard formats
- Query heterogeneous sources (Data Lake) using SPARQL – CSV, Parquet, MongoDB, Cassandra, JDBC (MySQL, SQL Server, etc.) are supported
- Support for multiple data partitioning techniques
- SPARQL querying via Sparqlify and Ontop
- Graph-parallel querying of RDF using SPARQL (1.0) via GraphX traversals (experimental)
- RDFS, RDFS Simple and OWL-Horst forward chaining inference
- RDF graph clustering with different algorithms
- Terminological decision trees (experimental)
- Knowledge graph embedding approaches: TransE (beta), DistMult (beta)
Noteworthy changes or updates since the previous release are:
- A data lake concept for querying heterogeneous data sources has been integrated into SANSA
- New clustering algorithms have been added and the interface for clustering has been unified
- Ontop RDB2RDF engine support has been added
- RDF data quality assessment methods have been substantially improved
- Dataset statistics calculation has been substantially improved
- Improved unit test coverage
Deployment and getting started:
- There are template projects for SBT and Maven for Apache Spark as well as for Apache Flink available to get started.
- The SANSA jar files are in Maven Central i.e. in most IDEs you can just search for “sansa” to include the dependencies in Maven projects.
- Example code is available for various tasks.
- We provide interactive notebooks for running and testing code via Docker.
We want to thank everyone who helped to create this release, in particular the projects HOBBIT, Big Data Ocean, SLIPO, QROWD, BETTER, BOOST, MLwin and Simple-ML.
Spread the word by retweeting our release announcement on Twitter. For more updates, please view our Twitter feed and consider following us.
Greetings from the SANSA Development Team
SANSA 0.4 (Semantic Analytics Stack) Released
We are happy to announce SANSA 0.4 – the fourth release of the Scalable Semantic Analytics Stack. SANSA employs distributed computing via Apache Spark and Flink in order to allow scalable machine learning, inference and querying capabilities for large knowledge graphs.
- Website: http://sansa-stack.net
- GitHub: https://github.com/SANSA-Stack
- Download: http://sansa-stack.net/downloads-usage/
- ChangeLog: https://github.com/SANSA-Stack/SANSA-Stack/releases
You can find the FAQ and usage examples at http://sansa-stack.net/faq/.
The following features are currently supported by SANSA:
- Reading and writing RDF files in N-Triples, Turtle, RDF/XML, N-Quad format
- Reading OWL files in various standard formats
- Support for multiple data partitioning techniques
- SPARQL querying via Sparqlify
- Graph-parallel querying of RDF using SPARQL (1.0) via GraphX traversals (experimental)
- RDFS, RDFS Simple, OWL-Horst, EL (experimental) forward chaining inference
- Automatic inference plan creation (experimental)
- RDF graph clustering with different algorithms
- Terminological decision trees (experimental)
- Anomaly detection (beta)
- Knowledge graph embedding approaches: TransE (beta), DistMult (beta)
Noteworthy changes or updates since the previous release are:
- Parser performance has been improved significantly e.g. DBpedia 2016-10 can be loaded in <100 seconds on a 7 node cluster
- Support for a wider range of data partitioning strategies
- A better unified API across data representations (RDD, DataFrame, DataSet, Graph) for triple operations
- Improved unit test coverage
- Improved distributed statistics calculation (see ISWC paper)
- Initial scalability tests on 6 billion triple Ethereum blockchain data on a 100 node cluster
- New SPARQL-to-GraphX rewriter aiming at providing better performance for queries exploiting graph locality
- Numeric outlier detection tested on DBpedia (en)
- Improved clustering tested on 20 GB RDF data sets
Deployment and getting started:
- There are template projects for SBT and Maven for Apache Spark as well as for Apache Flink available to get started.
- The SANSA jar files are in Maven Central i.e. in most IDEs you can just search for “sansa” to include the dependencies in Maven projects.
- Example code is available for various tasks.
- We provide interactive notebooks for running and testing code via Docker.
We want to thank everyone who helped to create this release, in particular the projects Big Data Europe, HOBBIT, SAKE, Big Data Ocean, SLIPO, QROWD, BETTER, BOOST and SPECIAL.
Spread the word by retweeting our release announcement on Twitter. For more updates, please view our Twitter feed and consider following us.
Greetings from the SANSA Development Team
SANSA Parser Performance Improved
More efficient RDF N-Triples Parser introduced in SANSA: Parsing Improvements of up to an order of Magnitude, e.g. DBpedia can be read in <100 seconds on a 7 node cluster
SANSA provides a set of different RDF serialization readers and for most of them, the Jena Riot Reader has been used. Unfortunately, this represented a bottleneck for a range of use cases on which SANSA has been applied when dozens of billions of triples need to be processed.
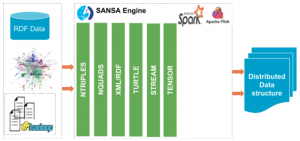
Fig. 1. Different RDF serialization readers supported on SANSA.
In order to improve the efficiency of the N-Triples reader, we have been working on a Spark-based implementation in the last weeks and are happy to announce that we could speed up the processing time up to an order of magnitude. As an example, the data currently loaded in the main public DBpedia endpoint (450 million triples) can be read in less than 100 seconds on 6 node cluster now. All improvements will be integrated on SANSA with the new version (SANSA 0.4), which we will ship end of June.
For people interested in performance details: We did some experiments during the development also on publicly available datasets which we can report here. We tested on three well known RDF datasets, namely LUBM, DBpedia, and Wikidata and measured the time it takes to read and distributed the datasets on the cluster. As you can see in the image below, we basically reduced the processing time of those data sets by up to an order of magnitude.
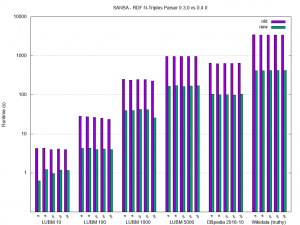
For future work, we will be working on the Flink part of the RDF layer to align its performance with the Spark implementation and investigating the relation to different optimization techniques like compression, partitioning strategies, etc. when working on Spark and Flink.
Datasets:
| Dataset | #triples |
| LUBM[note]The LUBM datasets have been generated via an improved version of the generator maintained by Rob Vesse and can be found on Github: https://github.com/rvesse/lubm-uba[/note] 10 | 1 316 342 |
| LUBM 100 | 13 876 156 |
| LUBM 1000 | 138 280 374 |
| LUBM 5000 | 690 895 862 |
| DBpedia 2016-10[note]We loaded the data which is also published on the public DBpedia SPARQL endpoint as described in http://wiki.dbpedia.org/public-sparql-endpoint[/note] | 451 685 478 |
| Wikidata (truthy)[note]Latest truthy taken from https://dumps.wikimedia.org/wikidatawiki/entities/latest-truthy.nt.bz2 ( we used version of May 07, 2018 )[/note] | 2 786 548 055 |
Experimental Settings:
- Server Setup: 7 nodes, 128 GB RAM, 16 physical cores
- Spark Setup: 1 master node, 6 slave nodes, Spark version 2.3.1
- Spark Submit Settings:
1234num-executors=5executor-memory=17Gexecutor-cores=5driver-memory=4G
SANSA Collaboration with Alethio
The SANSA team is excited to announce our collaboration with Alethio (a ConsenSys formation). SANSA is the major distributed, open source solution for RDF querying, reasoning and machine learning. Alethio is building an Ethereum analytics platform that strives to provide transparency over what’s happening on the Ethereum p2p network, the transaction pool and the blockchain and provide “blockchain archeology”. Their 5 billion triple data set contains large scale blockchain transaction data modelled as RDF according to the structure of the Ethereum ontology. EthOn – The Ethereum Ontology – is a formalization of concepts/entities and relations of the Ethereum ecosystem represented in RDF and OWL format. It describes all Ethereum terms including blocks, transactions, contracts, nonces etc. as well as their relationships. Its main goal is to serve as a data model and learning resource for understanding Ethereum.
Alethio is interested in using SANSA as a scalable processing engine for their large-scale batch and stream processing tasks, such as querying the data in real time via SPARQL and performing related analytics on a wide range of subjects (e.g. asset turnover for sets of accounts, attack pattern detection or Opcode usage statistics). At the same time, SANSA is interested in further industrial pilot applications for testing the scalability on larger datasets, mature its code base and gain experience on running the stack on production clusters. Specifically, the initial goal of Alethio was to load a 2TB EthOn dataset containing more than 5 billion triples and then performing several analytic queries on it with up to three inner joins. The queries are used to characterize movement between groups of ethereum accounts (e.g. exchanges or investors in ICOs) and aggregate their in and out value flow over the history of the Ethereum blockchain. The experiments were successfully run by Alethio on a cluster with up to 100 worker nodes and 400 cores that have a total of over 3TB of memory available.
“I am excited to see that SANSA works and scales well to our data. Now, we want to experiment with more complex queries and tune the Spark parameters to gain the optimal performance for our dataset” said Johannes Pfeffer, co-founder of Alethio. “I am glad that Alethio managed to run their workload and to see how well our methods scale to a 5 billion triple dataset”, added Gezim Sejdiu, PhD student at the Smart Data Analytics Group and SANSA core developer.
Parts of the SANSA team, including its leader Prof. Jens Lehmann as well as Dr. Hajira Jabeen, Dr. Damien Graux and Gezim Sejdiu, will now continue the collaboration together with the data science team of Alethio after those successful experiments. Beyond the above initial tests, we are jointly discussing possibilities for efficient stream processing in SANSA, further tuning of aggregate queries as well as suitable Apache Spark parameters for efficient processing of the data. In the future, we want to join hands to optimize the performance of loading the data (e.g. reducing the disk footprint of datasets using compression techniques allowing then more efficient SPARQL evaluation), handling the streaming data, querying, and analytics in real time.
The SANSA team is happily looking forward to further interesting scientific research as well as industrial adaptation.
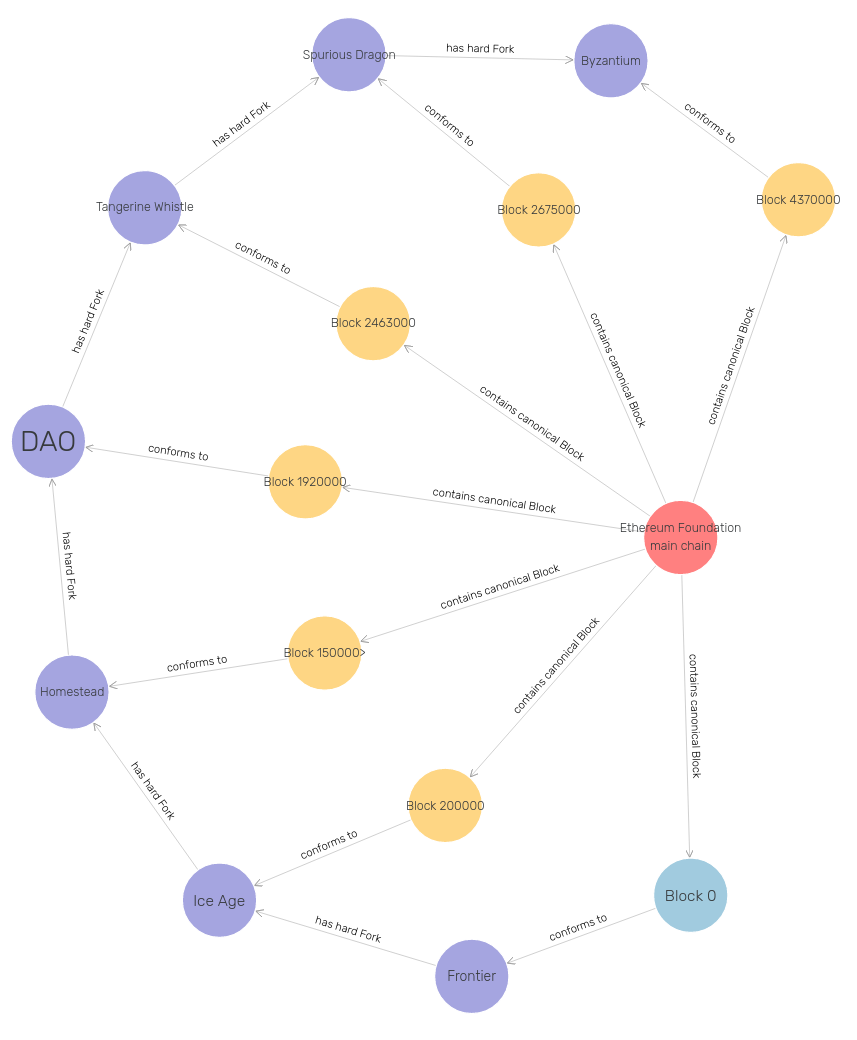
Core model of the fork history of the Ethereum Blockchain modeled in EthOn
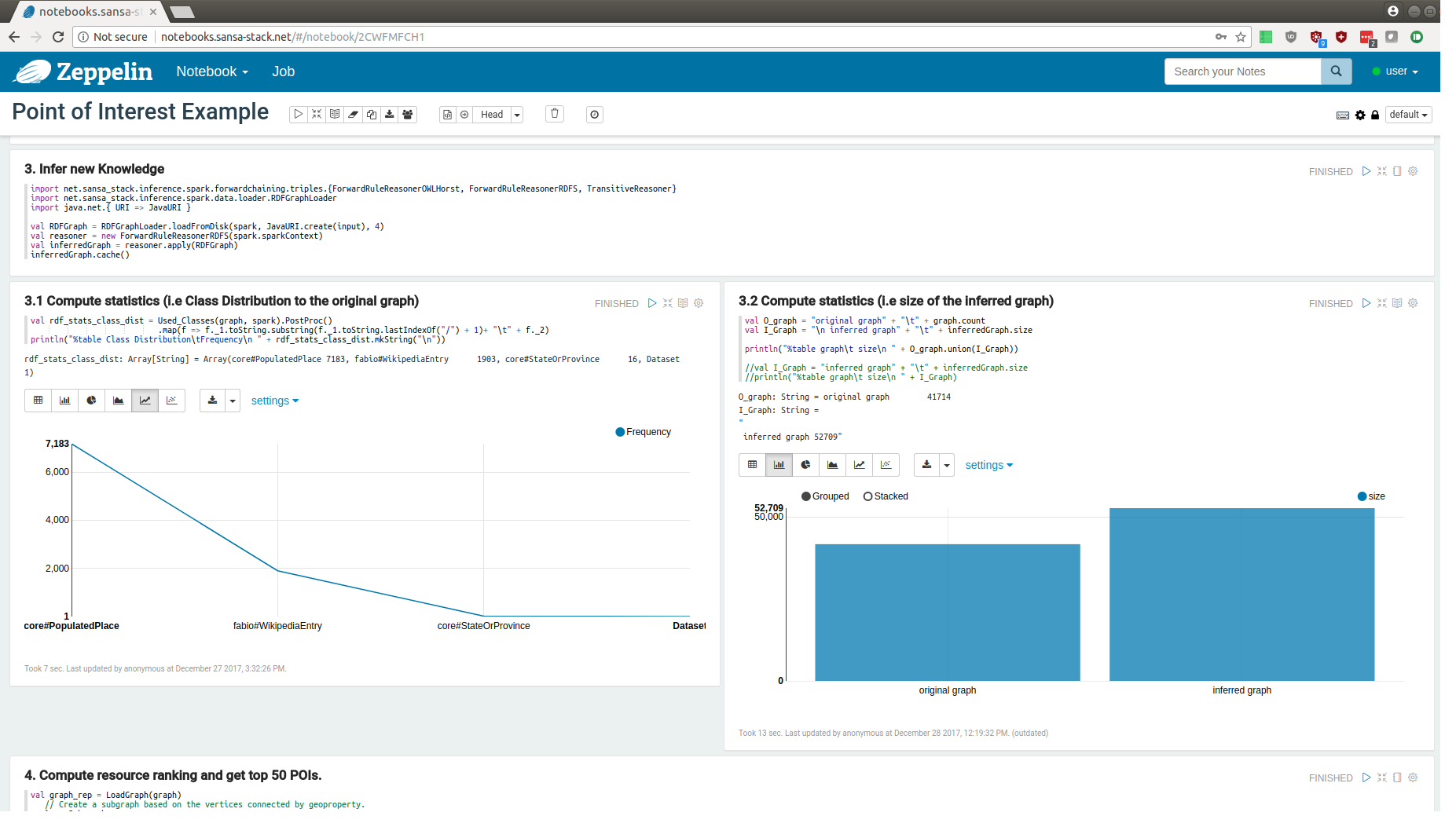
SANSA Notebooks
In this blog post, we highlight the demonstration of SANSA Notebooks. Semantic Analytics Stack (SANSA) is a project for developing open source algorithms for distributed data processing for large-scale RDF knowledge graphs.
SANSA Notebooks are interactive notebooks for the Spark subset of SANSA. The notebooks can be deployed locally following the instructions from the SANSA Notebooks Github repository. To demonstrate the capabilities of the notebooks, we provide the public installation on our servers. To login into the public demo deployment use user/user login and password. In the demo, you can navigate through the notebooks and view their results. The modification and execution of the notebooks are disabled for security reasons.
If you have questions feel free to open an issue on our issue tracker.
SANSA 0.3 (Semantic Analytics Stack) Released
We are happy to announce SANSA 0.3 – the third release of the Scalable Semantic Analytics Stack. SANSA employs distributed computing via Apache Spark and Flink in order to allow scalable machine learning, inference and querying capabilities for large knowledge graphs.
- Website: http://sansa-stack.net
- GitHub: https://github.com/SANSA-Stack
- Download: http://sansa-stack.net/downloads-usage/
- ChangeLog: https://github.com/SANSA-Stack/SANSA-Stack/releases
You can find the FAQ and usage examples at http://sansa-stack.net/faq/.
The following features are currently supported by SANSA:
- Reading and writing RDF files in N-Triples, Turtle, RDF/XML, N-Quad format
- Reading OWL files in various standard formats
- Support for multiple data partitioning techniques
- SPARQL querying via Sparqlify (with some known limitations until the next Spark 2.3.* release)
- SPARQL querying via conversion to Gremlin path traversals (experimental)
- RDFS, RDFS Simple, OWL-Horst (all in beta status), EL (experimental) forward chaining inference
- Automatic inference plan creation (experimental)
- RDF graph clustering with different algorithms
- Rule mining from RDF graphs based AMIE+
- Terminological decision trees (experimental)
- Anomaly detection (beta)
- Distributed knowledge graph embedding approaches: TransE (beta), DistMult (beta), several further algorithms planned
Deployment and getting started:
- There are template projects for SBT and Maven for Apache Spark as well as for Apache Flink available to get started.
- The SANSA jar files are in Maven Central i.e. in most IDEs you can just search for “sansa” to include the dependencies in Maven projects.
- There is example code for various tasks available.
- We provide interactive notebooks for running and testing code via Docker.
We want to thank everyone who helped to create this release, in particular the projects Big Data Europe, HOBBIT, SAKE, Big Data Ocean, SLIPO, QROWD and BETTER.
Greetings from the SANSA Development Team