What is SANSA?
SANSA is a big data engine for scalable processing of large-scale RDF data. SANSA uses Apache Spark which offers fault-tolerant, highly available and scalable approaches to efficiently process massive sized datasets. SANSA provides the facilities for Semantic data representation, Querying, Inference, and Analytics.
SANSA-Stack’s core is a data flow engine that provides data distribution and fault tolerance for distributed computations over RDF large-scale datasets.
SANSA includes several modules for creating applications:
- Read / Write RDF / OWL for RDF/OWL operations,
- Querying support a query language on top of distributed RDF/OWL library, as well as querying heterogeneous non-RDF data.
- Inference implements rule-based reasoning on RDF/OWL data,
- ML- Machine Learning for semantic aware analytics on RDF data
SANSA is easily integrated with well-known open source systems both for data input and output (HDFS) and is build on top of Spark.

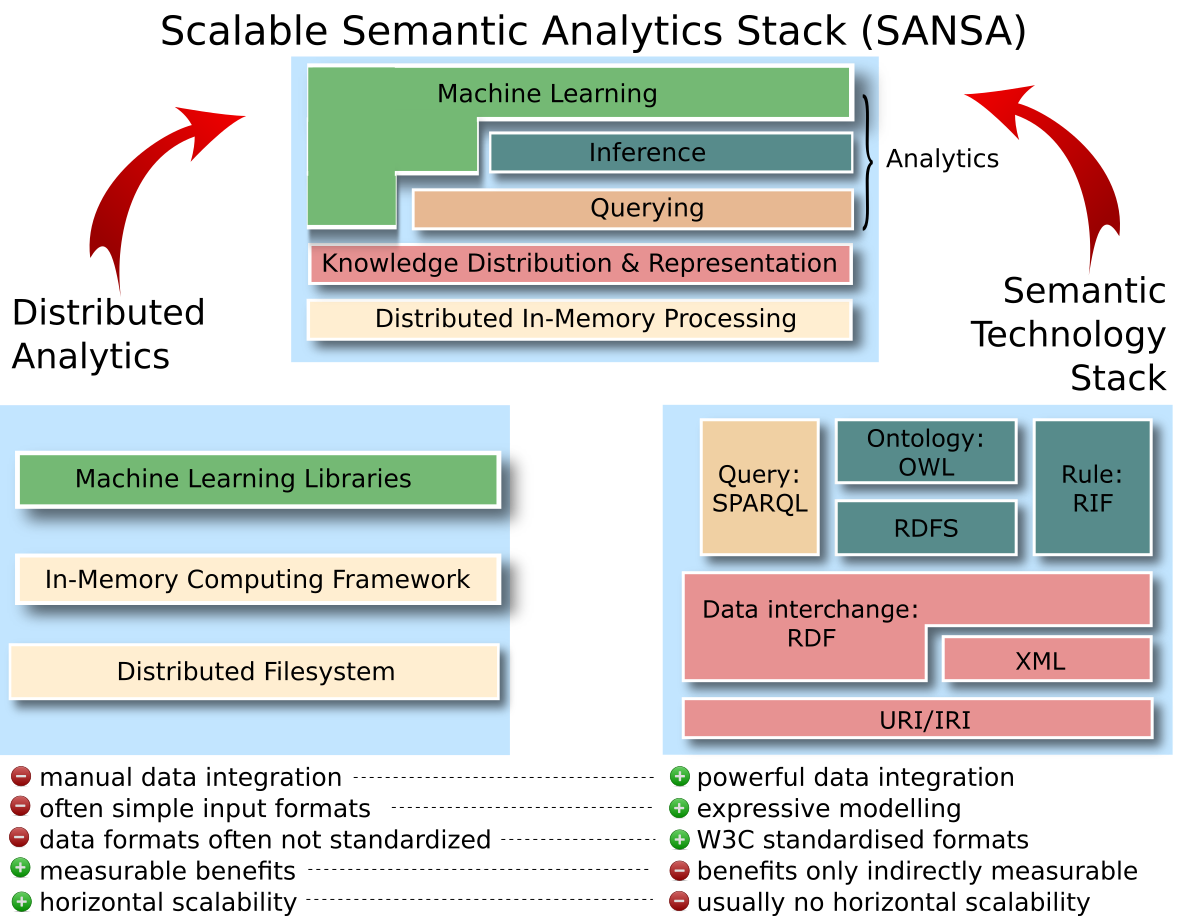
What is the idea behind SANSA?
In SANSA, we combine distributed computing frameworks (specifically Spark and Flink) with the semantic technology stack.
The SANSA vision combines distributed analytics (left) and semantic technologies (right) into a scalable semantic analytics stack (top). The colours encode what part of the two original stacks influence which part of the SANSA stack. The main objective of SANSA is to investigate whether the characteristics of each technology stack (bottom) can be combined to retain the respective advantages.
Why SANSA?
SANSA inherits the following advantages from the semantic technology
stack and machine learning research and distributed computing.
Powerful Data Integration
Current analytics pipelines have to handle increasing data variety and complexity more…
Expressive Modelling
The vast majority of machine learning algorithms have to rely on simple input more…
Measurable Benefits
A key driver for the success of machine learning
is that its benefits are often directly more…
Horizontal Scalability
Distributed in-memory computing can provide the
horizontal scalability required more…
Community
If you have question related to SANSA community then you can post in on various channels:
- Mailing List. Subscribe to the mailing list via @SANSA-Stack or by sending an e-mail message to sansa-stack+subscribe@googlegroups.com. Once the subscription was confirmed, you can send questions to sansa-stack@googlegroups.com.
- GitHub issues. Post your questions to GitHub Issues for the specific module.
Latest Blog Posts
- SANSA 0.7.1 (Semantic Analytics Stack) Released - We are happy to announce SANSA 0.7.1 - the seventh release… ...
- Squerall to SANSA-DataLake - For over four decades, relational data management remained a dominant… ...
- Quality Assessment of RDF Datasets at Scale - “Data is the new oil. It’s valuable, but if unrefined… ...
- SANSA 0.6 (Semantic Analytics Stack) Released - We are happy to announce SANSA 0.6 - the sixth… ...
- SANSA 0.5 (Semantic Analytics Stack) Released - We are happy to announce SANSA 0.5 - the fifth… ...


