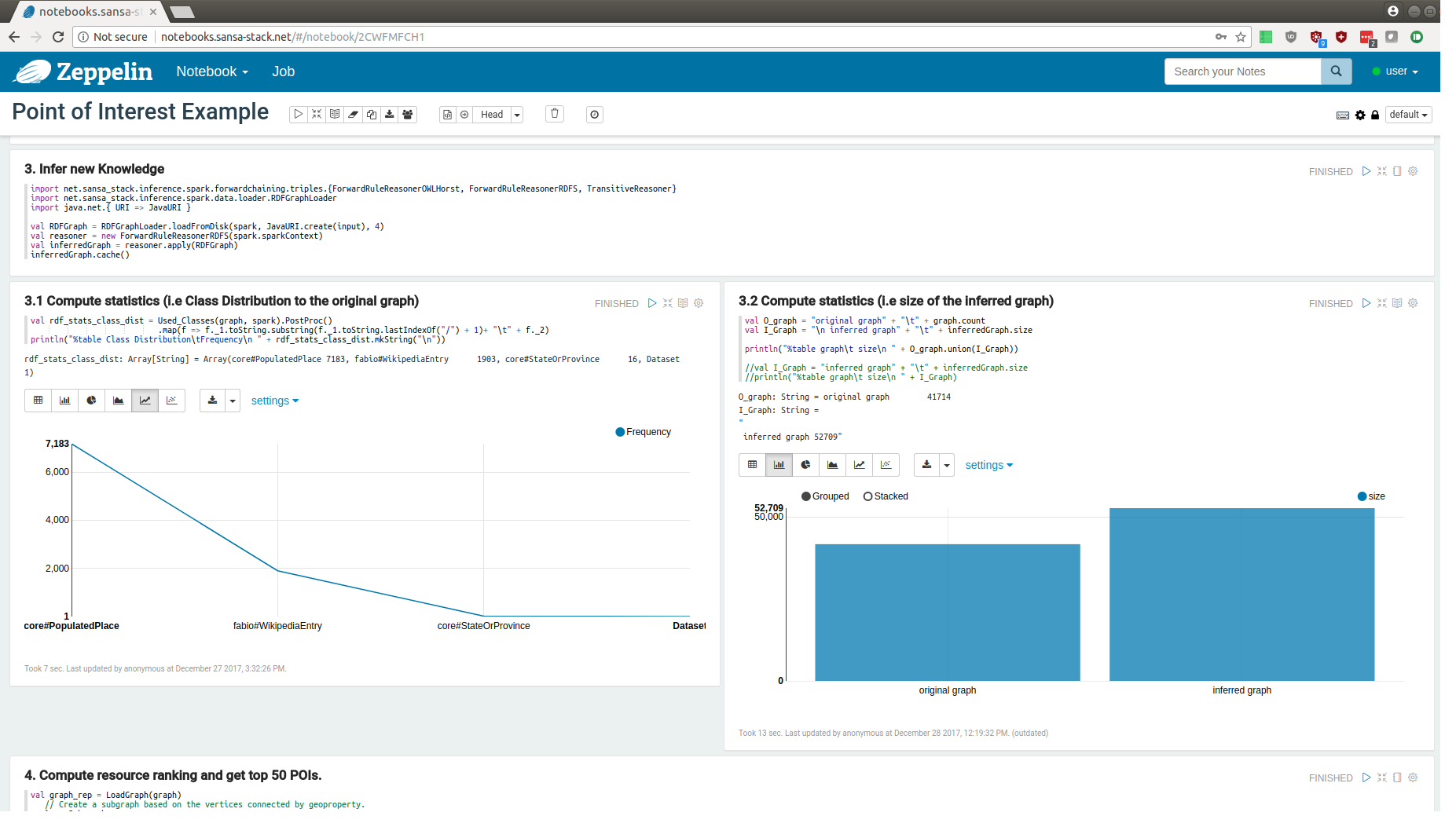
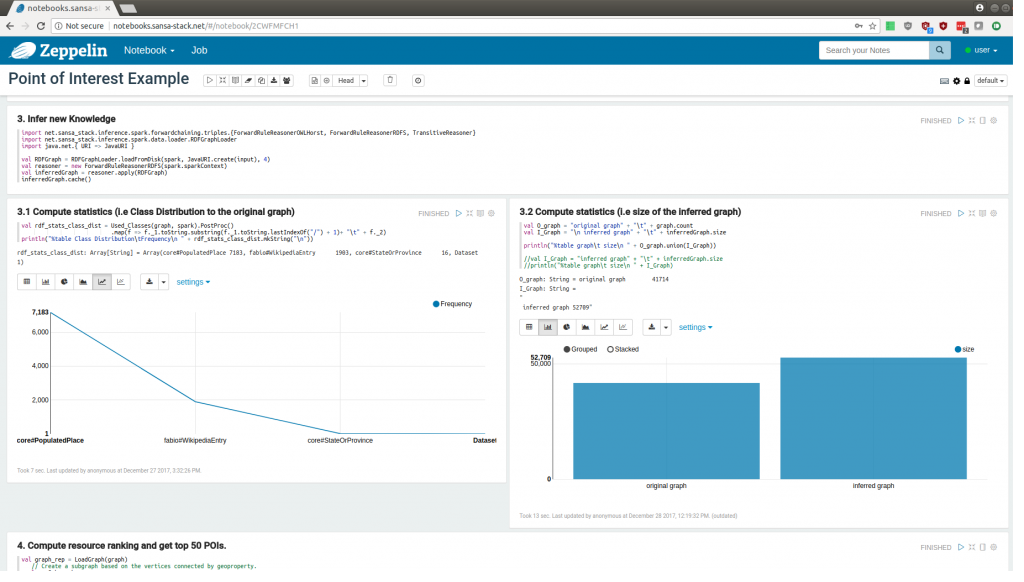
In this blog post, we highlight the demonstration of SANSA Notebooks. Semantic Analytics Stack (SANSA) is a project for developing open source algorithms for distributed data processing for large-scale RDF knowledge graphs.
SANSA Notebooks are interactive notebooks for the Spark subset of SANSA. The notebooks can be deployed locally following the instructions from the SANSA Notebooks Github repository. To demonstrate the capabilities of the notebooks, we provide the public installation on our servers. To login into the public demo deployment use user/user login and password. In the demo, you can navigate through the notebooks and view their results. The modification and execution of the notebooks are disabled for security reasons.
If you have questions feel free to open an issue on our issue tracker.