More efficient RDF N-Triples Parser introduced in SANSA: Parsing Improvements of up to an order of Magnitude, e.g. DBpedia can be read in <100 seconds on a 7 node cluster
SANSA provides a set of different RDF serialization readers and for most of them, the Jena Riot Reader has been used. Unfortunately, this represented a bottleneck for a range of use cases on which SANSA has been applied when dozens of billions of triples need to be processed.
Fig. 1. Different RDF serialization readers supported on SANSA.
In order to improve the efficiency of the N-Triples reader, we have been working on a Spark-based implementation in the last weeks and are happy to announce that we could speed up the processing time up to an order of magnitude. As an example, the data currently loaded in the main public DBpedia endpoint (450 million triples) can be read in less than 100 seconds on 6 node cluster now. All improvements will be integrated on SANSA with the new version (SANSA 0.4), which we will ship end of June.
For people interested in performance details: We did some experiments during the development also on publicly available datasets which we can report here. We tested on three well known RDF datasets, namely LUBM, DBpedia, and Wikidata and measured the time it takes to read and distributed the datasets on the cluster. As you can see in the image below, we basically reduced the processing time of those data sets by up to an order of magnitude.
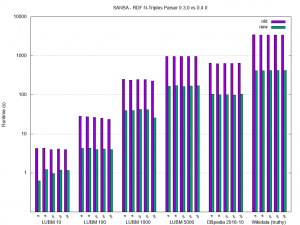
For future work, we will be working on the Flink part of the RDF layer to align its performance with the Spark implementation and investigating the relation to different optimization techniques like compression, partitioning strategies, etc. when working on Spark and Flink.
Datasets:
| Dataset | #triples |
| LUBM[note]The LUBM datasets have been generated via an improved version of the generator maintained by Rob Vesse and can be found on Github: https://github.com/rvesse/lubm-uba[/note] 10 | 1 316 342 |
| LUBM 100 | 13 876 156 |
| LUBM 1000 | 138 280 374 |
| LUBM 5000 | 690 895 862 |
| DBpedia 2016-10[note]We loaded the data which is also published on the public DBpedia SPARQL endpoint as described in http://wiki.dbpedia.org/public-sparql-endpoint[/note] | 451 685 478 |
| Wikidata (truthy)[note]Latest truthy taken from https://dumps.wikimedia.org/wikidatawiki/entities/latest-truthy.nt.bz2 ( we used version of May 07, 2018 )[/note] | 2 786 548 055 |
Experimental Settings:
- Server Setup: 7 nodes, 128 GB RAM, 16 physical cores
- Spark Setup: 1 master node, 6 slave nodes, Spark version 2.3.1
- Spark Submit Settings:
1234num-executors=5executor-memory=17Gexecutor-cores=5driver-memory=4G