
SANSA at ISWC 2017 and a Demo Award
![]()
The International Semantic Web Conference (ISWC) is the premier international forum where Semantic Web / Linked Data researchers, practitioners, and industry specialists come together to discuss, advance, and shape the future of semantic technologies on the web, within enterprises and in the context of the public institution.
We are very pleased to announce that we got a paper accepted at ISWC 2017 for presentation at the main conference. Additionally, we also had a Demo paper accepted as well.
“Distributed Semantic Analytics using the SANSA Stack” by Jens Lehmann, Gezim Sejdiu, Lorenz Bühmann, Patrick Westphal, Claus Stadler, Ivan Ermilov, Simon Bin, Muhammad Saleem, Axel-Cyrille Ngonga Ngomo and Hajira Jabeen.
Prof. Dr. Jens Lehmann presented a work done on SANSA project with the main focus on offering a compact scalable engine for the whole Semantic Web Stack. The audience showed a high interest on the project, Room was very packed, a lot of people even standing ; around 150 attendees.
@JLehmann82 presenting @SANSA_Stack, a Semantic Component in the @BigData_Europe Platform solution at #iswc2017. Demo scheduled later! pic.twitter.com/EaFh6iJeQI
— Big Data Europe (@BigData_Europe) October 23, 2017
Website: http://sansa-stack.net/
GitHub: https://github.com/SANSA-Stack
Slides:https://www.slideshare.net/JensLehmann/sansa-iswc-international-semantic-web-conference-2017-talk
Furthermore, we are very happy to announce that we won the Best Demo Award for the SANSA Notebooks:
“The Tale of Sansa Spark” by Ivan Ermilov, Jens Lehmann, Gezim Sejdiu, Buehmann Lorenz, Patrick Westphal, Claus Stadler, Simon Bin, Nilesh Chakraborty, Henning Petzka, Muhammad Saleem, Axel-Cyrille Ngonga Ngomo and Hajira Jabeen.
Best demo #iswc2017 pic.twitter.com/skyGw9YK4v
— iswc2017 (@iswc2017) October 25, 2017
Here are some further pointers in case you want to know more about SANSA:
- Website: http://sansa-stack.net/
- GitHub: https://github.com/SANSA-Stack
- Slides:https://www.slideshare.net/GezimSejdiu/the-tale-of-sansa-spark-iswc-2017-demo
- Screencasts: https://www.youtube.com/watch?v=aHCoWmzUJlE&t=2s
The audience displayed enthusiasm during the demonstration appreciating the work and asking questions regarding the future of SANSA, technical details and possible synergy with industrial partners and projects. Gezim Sejdiu and Jens Lehmann, who were presenting the demo, were talking 3+ hours non-stop (without even time to eat 😉 ).
ISWC17 was a great venue to meet the community, create new connections, talk about current research challenges, share ideas and settle new collaborations.
SANSA 0.2 (Semantic Analytics Stack) Released
The Smart Data Analytics group is happy to announce SANSA 0.2 – the second release of the Scalable Semantic Analytics Stack. SANSA employs distributed computing for semantic technologies in order to allow scalable machine learning, inference and querying capabilities for large knowledge graphs.
- Website: http://sansa-stack.net
- GitHub: https://github.com/SANSA-Stack
- Download: http://sansa-stack.net/downloads-usage/
- ChangeLog: https://github.com/SANSA-Stack/SANSA-Stack/releases
You can find the FAQ and usage examples at http://sansa-stack.net/faq/.
The following features are currently supported by SANSA:
- Reading and writing RDF files in N-Triples format
- Reading OWL files in various standard formats
- Querying and partitioning based on Sparqlify
- RDFS/RDFS Simple/OWL-Horst forward chaining inference
- RDF graph clustering with different algorithms
- Rule mining from RDF graphs
Deployment and getting started:
- There are template projects for SBT and Maven for Apache Spark as well as for Apache Flink available to get started.
- The SANSA jar files are in Maven Central i.e. in most IDEs you can just search for “sansa” to include the dependencies in Maven projects.
- There is example code for various tasks available.
- We provide interactive notebooks for running and testing code via Docker.
We want to thank everyone who helped to create this release, in particular, the projects Big Data Europe, HOBBIT , SAKE and Big Data Ocean.
SANSA @ 4th Big Data Europe Plenary at Leipzig University
![]() The meeting, hosted by our partner InfAI e. V., took place on the 14th and 15th of December at the University of Leipzig.
The meeting, hosted by our partner InfAI e. V., took place on the 14th and 15th of December at the University of Leipzig.
The 29 attendees in total, including 15 partners, discussed and reviewed the progress of all work packages in 2016 and planned the activities and workshops taking place in the next six months.
During the first day of the meeting, Prof. Dr. Jens Lehmann presented the current status of SANSA.
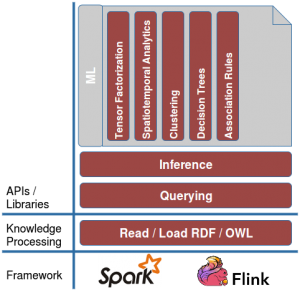
The audience showed high interest in his presentation and appreciated the usage of distributed frameworks applied on the Web of Data.The following discussion included further challenges on SANSA specific layers and constructive suggestions for possible improvements.
SANSA 0.1 (Semantic Analytics Stack) Released
Dear all,
We’re very happy to announce SANSA 0.1 – the initial release of the Scalable Semantic Analytics Stack. SANSA combines distributed computing and semantic technologies in order to allow powerful machine learning, inference and querying capabilities for large knowledge graphs.
Website: http://sansa-stack.net
GitHub: https://github.com/SANSA-Stack
Download: http://sansa-stack.net/downloads-usage/
ChangeLog: https://github.com/SANSA-Stack/SANSA-Stack/releases
You can find the FAQ and usage examples at http://sansa-stack.net/faq/.
The following features are currently supported by SANSA:
- Support for reading and writing RDF files in N-Triples format
- Support for reading OWL files in various standard formats
- Querying and partitioning based on Sparqlify
- Support for RDFS/RDFS Simple/OWL-Horst forward chaining inference
- Initial RDF graph clustering support
- Initial support for rule mining from RDF graphs
Visit the release notes to read about the new features, or download the release today.
We want to thank everyone who helped to create this release, in particular, the projects Big Data Europe, HOBBIT and SAKE.
Kind regards,