“Data is the new oil. It’s valuable, but if unrefined it cannot really be used. It has to be changed into gas, plastic, chemicals, etc to create a valuable entity that drives profitable activity; so must data be broken down, analyzed for it to have value.”
— Clive Humby (UK Mathematician and Chief Data Scientist at Starcount)
Extracting meaningful information from data which is considered being chaos has been a challenge for many years now. Often, this data is coming in an unstructured form and is increasing daily, there is a challenge to analyze and use such data. Data quality issues (when dealing with such amount of data) becomes a challenge in the data world. Such unstructured data acquired from different sources often causes a delay in deriving insights and analysis due to data quality issues.
In order to handle this ambiguity and complexity of data is modeling using the Semantic Web Technologies. Over the last years, Linked Data has grown continuously. Today, we count more than 10,000 datasets being available online following Linked Data standards. These standards allow data to be machine-readable and interoperable. Nevertheless, many applications, such as data integration, search, and interlinking, cannot take full advantage of Linked Data if it is of low quality. There exist a few approaches for the quality assessment of Linked Data, but their performance degrades with the increase in data size and quickly grows beyond the capabilities of a single machine.
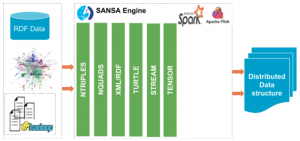
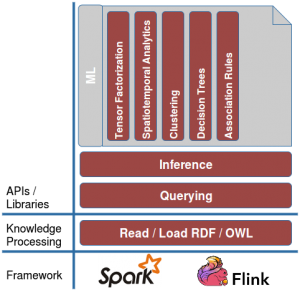
In order to overcome this, we present DistQualityAssessment [1] — an open-source implementation of quality assessment of large RDF datasets (integrated into SANSA) that can scale out to a cluster of machines.
Getting Started
Within the scope of this post, we will be using SANSA-Notebooks as a base setup for running SANSA and in particular distributed quality assessment. You can also run it using your prefered IDE (see here for more details on how to setup SANSA on IDE).
SANSA Notebooks (or SANSA Workbench) is an interactive Spark Notebooks for running SANSA-Examples and are easy to deploy with docker-compose. Deployment stack includes Hadoop for HDFS, Spark for running SANSA examples, Hue for navigation and copying file to HDFS. The notebooks are created and run using Apache Zeppelin. The setup requires that you have “Docker Engine >= 1.13.0, docker-compose >= 1.10.0, and around 10 GB of disk space for Docker images”.
After you are done with the docker installation, clone the SANSA-Notebooks git repository:
|
1 2 |
git clone https://github.com/SANSA-Stack/SANSA-Notebooks cd SANSA-Notebooks |
Get the SANSA Examples jar file (requires wget):
|
1 |
make |
Start the cluster (this will lead to downloading BDE docker images):
|
1 |
make up |
When start-up is done you will be able to access the SANSA notebooks.
To load the data to your cluster simply do:
|
1 |
make load-data |
After you load the data (you can upload your own data using Hue – HDFS File Browser or simply adding them to the folder and run the command above to lead the data), go on and open SANSA Notebooks, choose any available notebooks or create a new one (choose Spark as Interpreter) and add the following code snippets:
|
1 2 3 4 5 6 7 |
import org.apache.jena.riot.Lang import net.sansa_stack.rdf.spark.io._ import net.sansa_stack.rdf.spark.qualityassessment._ val input = "hdfs://namenode:8020/data/rdf.nt" val lang = Lang.NTRIPLES val triples = spark.rdf(lang)(input) |
In order to read data in an efficient and scalable way, SANSA has its own readers for reading different RDF serialization formats. In our case, we are going to use NTRIPLES (see Line 5). For that reason, we have to import io API (see Line 2) in order to use such io operations.
As the data is kept in HDFS, we will have to specify the path where data is standing (see Line 5) and the syntax they are represented (in our case we are using NTRIPLES, see Line 6). Afterword, we generate Spark RDD (Resilient Distributed Datasets) representations of Triples (see Line 7) which allows us to perform a quality assessment at scale.
The SANSA quality assessment component is part of the framework and therefore the call can be done easily by just using the qualityassessment namespace (see Line 3). It comes with different quality assessment metrics which can be easily used. Below, we list part of that list:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
// compute quality assessment val completeness_schema = triples.assessSchemaCompleteness() val completeness_interlinking = triples.assessInterlinkingCompleteness() val completeness_property = triples.assessPropertyCompleteness() val syntacticvalidity_literalnumeric = triples.assessLiteralNumericRangeChecker() val syntacticvalidity_XSDDatatypeCompatibleLiterals = triples.assessXSDDatatypeCompatibleLiterals() val availability_DereferenceableUris = triples.assessDereferenceableUris() val relevancy_CoverageDetail = triples.assessCoverageDetail() val relevancy_CoverageScope = triples.assessCoverageScope() val relevancy_AmountOfTriples = triples.assessAmountOfTriples() val performance_NoHashURIs = triples.assessNoHashUris() val understandability_LabeledResources = triples.assessLabeledResources() |
The quality assessment metric evaluation generate a numerical representation of the quality check. Here, for example we want to assess the Schema Completeness (see Quality Assessment for Linked Open Data: A Survey paper for more details on the metric definitions) on a given dataset. We can assess it by just running:
|
1 |
val completeness_schema = triples.assessSchemaCompleteness() |
Within the SANSA Notebooks, we can visualize the metric values and export the results if needed for further analysis.

For more details about the architecture, technical details of the approach and its evaluation/comparison with other systems, please check out our paper [1].
After you are done, you can stop the whole stack:
|
1 |
make down |
That’s it, hope you enjoyed it. If you have any question or suggestion, or you are planning a project with SANSA, perhaps by using this quality assessment? We would love to hear about it! b.t.w we always welcome new contributors to the project! Please see our contribution guide for more details on how to get started contributing to SANSA.
References
[1]. In Proceedings of 18th International Semantic Web Conference, 2019.
|
1 2 3 4 5 6 7 8 9 |
@InProceedings{sejdiu-2019-sansa-dist-quality-assessment-iswc, Title = {A {S}calable {F}ramework for {Q}uality {A}ssessment of {RDF} {D}atasets}, Author = {Gezim Sejdiu and Anisa Rula and Jens Lehmann and Hajira Jabeen}, Booktitle = {Proceedings of 18th International Semantic Web Conference}, Year = {2019}, Keywords = {2019 sansa sejdiu rula jabeen lehmann group_sda}, Url = {http://jens-lehmann.org/files/2019/iswc_dist_quality_assessment.pdf}, UrlSlides = {https://www.slideshare.net/GezimSejdiu/a-scalable-framework-for-quality-assessment-of-rdf-datasets-iswc-2019-talk} } |