Introduction
Over the last decade, the Semantic Web has grown from a mere idea for modeling data in the web, into an established field of study driven by a wide range of standards and protocols for data consumption, publication, and exchange on the Web.
For the record, today we count more than 10,000 datasets openly available online using Semantic Web standards.
Thanks to such standards, large datasets became machine-readable. Nevertheless, many applications such as data integration, search, and interlinking may not take full advantage of the data without having a priori statistical information about its internal structure and coverage. RDF datasets statistics can be beneficial in many ways, for example, 1) Vocabulary reuse (suggesting frequently used similar vocabulary terms in other datasets during dataset creation), 2) Quality analysis (analysis of incoming and outcoming links in RDF datasets to establish hubs similar to what pagerank has achieved in the traditional web), 3) Coverage analysis (verifying whether frequent dataset properties cover all similar entities and other related tasks), 4) privacy analysis (checking whether property combinations may allow to uniquely identify persons in a dataset) and 5) link target analysis (finding datasets with similar characteristics, e.g.~similar frequent properties) for interlinking candidates.
A number of solutions have been conceived to offer users such statistics about RDF vocabularies and datasets. However, those efforts showed severe deficiencies in terms of performance when the dataset size goes beyond the main memory size of a single machine. This limits their capabilities to medium-sized datasets only, which paralyzes the role of applications in embracing the increasing volumes of the available datasets.
As the memory limitation was the main shortcoming in the existing works, we investigated parallel approaches that distribute the workload among several separate memories.
One solution that gained traction over the past years is the concept of Resilient Distributed Dataset (RDDs), which are in-memory data structures. Using RDDs, we are able to perform operations on the whole dataset stored in a significantly enlarged distributed memory.
Apache Spark is an implementation of the concept of RDDs. It allows performing coarse-grained operations over voluminous datasets in a distributed manner in parallel.
We introduce an approach for statistical evaluation of large RDF datasets, which scales out to clusters of multiple machines.
Architecture
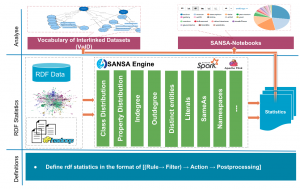
Fig. 1. Overview of DistLODStats’s abstract architecture.
Distributed LODStats comprises three main phases depicted in Fig.1. First, reading RDF data (e.g. NTriples file) from HDFS and converting it into a triples RDD (and RDD of type Triples<Subject, Property, Object>, as known as main dataset. Second, this latter undergoes a Filtering operation applying the Rule’s Filter and producing a new filtered RDD. Third, the filtered RDD will serve as an input to the next step: Computing where the rule’s action and/or post-processing are effectively applied. The output of the Computing phase will be the statistical results represented in a human-readable format.
Furthermore, we provide a Docker image of the system integrated within the BDE platform – an open source Big Data Processing Platform allowing users to install numerous big data processing tools and frameworks and create working dataflow applications.
The work done here has been integrated into SANSA, an open source data flow processing engine for performing distributed computation over large-scale RDF datasets. It provides data distribution, communication, and fault tolerance for manipulating massive RDF graphs and applying machine learning algorithms on the data at scale.