Semantic Analytics Stack (SANSA)
Open Source Algorithms for Distributed Data Processing for Large-scale RDF Knowledge Graphs

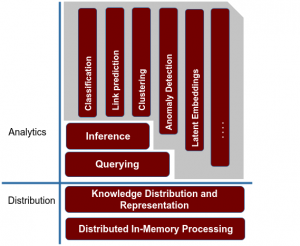
Getting Started
Download the latest release and run SANSA on your machine, cluster or the cloud:
The documentation provided on setup guide give an overview for all deployment options.

![]()
![]()
![]()