SANSA Frequently Asked Questions (FAQ)
The following questions are frequently asked with regard to the SANSA project in general. If you have further questions, make sure to have a look the documentation or ask the community.
- General
- RDF Processing
- How does the distribution of RDF data in SANSA work?
- How can I read an RDF file and retrieve a Spark RDD representation of it?
- Does SANSA support different serialisation formats for RDF?
- How can I collect RDF dataset statistics on SANSA?
- How can I filter all triples with a certain subject / predicate / object in an RDF file?
- How can I count the number of subjects / predicates / objects / triples of my RDF file?
- How can I apply a user defined function to all literals / URIs?
- How can I search for entities?
- Can I load several files without merging them beforehand?
- How do I write RDF files?
- How can I compute the pagerank of resources in RDF files?
- OWL Processing
- SPARQL Queries
- Inference
- Machine Learning
General
1. What does SANSA stand for?
Semantic Analytics Stack
Here, we see analytics as the combination of querying, inference and machine learning tasks.
2. Is the project inspired by Game of Thrones?
Any relationship between the SANSA Stack (or SANSA on Spark) and the character Sansa Stark in the above series is purely coincidental.
3. What is the idea behind SANSA?
In SANSA, we combine distributed computing frameworks (specifically Spark and Flink) with the semantic technology stack. Here is an illustration:
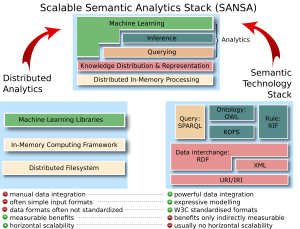
The SANSA vision combines distributed analytics (left) and semantic technologies (right) into a scalable semantic analytics stack (top). The colours encode what part of the two original stacks influence which part of the SANSA stack. The main objective of SANSA is to investigate whether the characteristics of each technology stack (bottom) can be combined to retain the respective advantages.
4. Why is SANSA useful?
The combination of distributed computing and semantic technologies has the potential to exploit several critical advantages. We are clearly not there yet, but initial steps have already been made.
SANSA inherits the following advantages from the semantic technology stack:
a) Powerful Data Integration: Current analytics pipelines have to handle increasing data variety and complexity. Moving from common short term ad hoc solutions that require a lot of engineering effort, to standardised and well-understood semantic technology approaches had and will have significant impact.
b) Expressive Modelling: The vast majority of machine learning algorithms have to rely on simple input formats, such as feature vectors, rather than being able to use expressive modelling via the Resource Description Framework (RDF) and the Web Ontology Language (OWL). While this has been researched in fields such as Statistical Relational Learning and Inductive Logic Programming, these methods usually do not scale horizontally. Initial work on horizontally scalable machine learning on structured data has been performed, particularly in terms of adding graph processing capabilities to distributed computing frameworks, but those are not aimed at semantic technologies and currently provide limited capabilities.
c) Standards: The usage of W3C standards can generally reduce pre-processing time in those cases when data sources are used for more than one analytics task. This is the case for knowledge graphs, which are often combined with several applications including search, information retrieval, advanced querying and filtering of information, as well as visualisation. Beyond this, the standardisation allows to draw on generic approaches, e.g. for querying and merging data, rather than developing ad hoc solutions, which are less reusable and often less efficient and effective. The use of standards will also enable a clearer separation of the data pre-processing step, i.e. RDF modelling, and the actual analytics step. This allows experts in either step to focus efforts on their expertise, increasing overall efficiency.
SANSA inherents the following advantages from machine learning research and distributed computing:
d) Measurable Benefits: A key driver for the success of machine learning is that its benefits are often directly measurable, e.g. an accuracy improvement can often be directly translated into a financial benefit. This is not really the case for semantic technologies where the benefits gained through the effort of modelling, editing and extracting knowledge are often not easily measurable. A seamless integration of semantic technologies and machine learning, as envisioned in SANSA, will also help to make the benefits of semantic technologies more visible, as they will translate to machine learning results which are more accurate and easier to understand.
e) Horizontal Scalability: Distributed in-memory computing can provide the horizontal scalability required by the high computation and storage demands of large-scale semantic knowledge graphs analytics. However, it does not magically result in higher scalability and requires a deep understanding of the underlying structures and models. For instance, distributed machine learning for expressive logics and the inclusion of inference in knowledge graph embedding models are challenging problems with many open research questions.
5. What architecture does SANSA use?
SANSA uses a technology stack consisting of several layers as shown below:
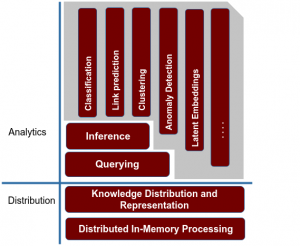
6. How can I use SANSA?
https://github.com/SANSA-Stack/SANSA-Stack
Back to top
RDF Processing
0. How does the distribution of RDF data in SANSA work?
SANSA uses the RDF data model for representing graphs consisting of triples with subject, predicate and object. RDF datasets may contains multiple RDF graphs and record information about each graph, allowing any of the upper layers of sansa (Querying and ML) to make queries that involve information from more than one graph. Instead of directly dealing with RDF datasets, the target RDF datasets need to be converted into an RDD of triples. We name such an RDD a main dataset. The main dataset is based on an RDD data structure, which is a basic building block of the Spark framework. RDDs are in-memory collections of records that can be operated on in parallel on large clusters.
1. How can I read an RDF file and retrieve a Spark RDD representation of it?
-
In this example, we use a few transformations to build a dataset of RDD[Triple] called triplesRDD and then print out list of triples.
1234567import net.sansa_stack.rdf.spark.io.NtripleReaderval input = "hdfs://..."val triplesRDD = NTripleReader.load(spark, URI.create(input))triplesRDD.take(5).foreach(println(_))Full example code: https://github.com/SANSA-Stack/SANSA-Examples/blob/master/sansa-examples-spark/src/main/scala/net/sansa_stack/examples/spark/rdf/TripleReader.scala
-
1234567import net.sansa_stack.rdf.flink.data.{RDFGraphLoader,RDFGraphWriter}// load triples from diskval graph = RDFGraphLoader.loadFromFile(input.getAbsolutePath, env)graph.print()
2. Does SANSA support different serialisation formats for RDF?
The following RDF formats are supported by SANSA.
- N-Triples
- N-Quads
In addition, we are working on generalization of TripleWritter and TripleReader.
3. How can I collect RDF dataset statistics on SANSA?
12345678import net.sansa_stack.rdf.spark.stats.RDFStatisticsval triples = NTripleReader.load(spark, URI.create(input))// compute criteriasval rdf_statistics = RDFStatistics(triples, spark)val stats = rdf_statistics.run()rdf_statistics.voidify(stats, rdf_stats_file, output)
Full example code: https://github.com/SANSA-Stack/SANSA-Examples/blob/master/sansa-examples-spark/src/main/scala/net/sansa_stack/examples/spark/rdf/RDFStats.scala-
123456789import net.sansa_stack.rdf.flink.stats.RDFStatisticsval env = ExecutionEnvironment.getExecutionEnvironmentval rdfgraph = RDFGraphLoader.loadFromFile(input, env)// compute criteriasval rdf_statistics = RDFStatistics(rdfgraph, env)val stats = rdf_statistics.run()rdf_statistics.voidify(stats, rdf_stats_file, output)
Full example code: https://github.com/SANSA-Stack/SANSA-Examples/blob/master/sansa-examples-flink/src/main/scala/net/sansa_stack/examples/flink/rdf/RDFStats.scala
4. How can I filter all triples with a certain subject / predicate / object in an RDF file?
-
12345678910val graph:TripleRDD = NTripleReader.load(spark, URI.create(input))//Triples filtered by subject ( "http://dbpedia.org/resource/Charles_Dickens" )println("All triples related to Dickens:\n" + graph.find(URI("http://dbpedia.org/resource/Charles_Dickens"), ANY, ANY).collect().mkString("\n"))//Triples filtered by predicate ( "http://dbpedia.org/ontology/influenced" )println("All triples for predicate influenced:\n" + graph.find(ANY, URI("http://dbpedia.org/ontology/influenced"), ANY).collect().mkString("\n"))//Triples filtered by object ( <http://dbpedia.org/resource/Henry_James> )println("All triples influenced by Henry_James:\n" + graph.find(ANY, ANY, URI("<http://dbpedia.org/resource/Henry_James>")).collect().mkString("\n"))
Full example code: https://github.com/SANSA-Stack/SANSA-Examples/blob/master/sansa-examples-spark/src/main/scala/net/sansa_stack/examples/spark/rdf/TripleOps.scala
-
123456789val rdfgraph = RDFGraphLoader.loadFromFile(input, env)//Triples filtered by subject ( "http://dbpedia.org/resource/Charles_Dickens" )println("All triples related to Dickens:\n" + rdfgraph.find(Some("http://commons.dbpedia.org/resource/Category:Places"), None, None).collect().mkString("\n"))//Triples filtered by predicate ( "http://dbpedia.org/ontology/influenced" )println("All triples for predicate influenced:\n" + rdfgraph.find(None, Some("http://dbpedia.org/ontology/influenced"), None).collect().mkString("\n"))//Triples filtered by object ( <http://dbpedia.org/resource/Henry_James> )println("All triples influenced by Henry_James:\n" + rdfgraph.find(None, None, Some("<http://dbpedia.org/resource/Henry_James>")).collect().mkString("\n"))
Full example code: https://github.com/SANSA-Stack/SANSA-Examples/blob/master/sansa-examples-flink/src/main/scala/net/sansa_stack/examples/flink/rdf/TripleOps.scala
5. How can I count the number of subjects / predicates / objects / triples of my RDF file?
-
1234println("Number of triples: " + graph.find(ANY, ANY, ANY).distinct.count())println("Number of subjects: " + graph.getSubjects.distinct.count())println("Number of predicates: " + graph.getPredicates.distinct.count())println("Number of objects: " + graph.getObjects.distinct.count())
-
1234//println("Number of triples: " + rdfgraph.triples.distinct.count())println("Number of subjects: " + rdfgraph.getSubjects.map(_.toString).distinct().count)println("Number of predicates: " + rdfgraph.getPredicates.map(_.toString).distinct.count())println("Number of objects: " + rdfgraph.getPredicates.map(_.toString).distinct.count())
6. How can I apply a user defined function to all literals / URIs?
-
By implementing your udf into :
12graph.mapLiterals { x => ??? }graph.mapURIs { x => ??? }
7. How can I search for entities?
-
By applying your filter operations over:
123graph.filterSubjects { x => ??? }graph.filterObjects { x => ??? }graph.filterPredicates { x => ??? }
8. Can I load several files without merging them beforehand?
-
In Spark, the method textFile() takes an URI for the file (either a local path or a hdfs:// ). You could run this method on a single file or a directory which may contains more than one file by calling :
12val rdfFile = sc.textFile("hdfs://.../yourdirectory/yourfile.nt")val rdfDirectory = sc.textFile("hdfs://.../yourdirectory/")
9. How do I write RDF files?
-
12345import net.sansa_stack.rdf.spark.io.NTripleReaderval triplesRDD = NTripleReader.load(spark, URI.create(input))triplesRDD.saveAsTextFile(output)
Full example code: https://github.com/SANSA-Stack/SANSA-Examples/blob/master/sansa-examples-spark/src/main/scala/net/sansa_stack/examples/spark/rdf/TripleWriter.scala
-
1234import net.sansa_stack.rdf.flink.data.RDFGraphWriter// write triples to diskRDFGraphWriter.writeToFile(graph, output.getAbsolutePath)
Full example code: https://github.com/SANSA-Stack/SANSA-Examples/blob/master/sansa-examples-spark/src/main/scala/net/sansa_stack/examples/spark/rdf/TripleWriter.scala
10. How can I compute the pagerank of resources in RDF files?
-
The PageRank algorithm compute the importance of each vertex (represented as resource) in a graph. Resource PageRank is build on top of Spark GraphX.
12345678910111213import net.sansa_stack.rdf.spark.io.NTripleReaderval triplesRDD = NTripleReader.load(spark, URI.create(input))val graph = makeGraph(triplesRDD)val pagerank = graph.pageRank(0.00001).verticesval report = pagerank.join(graph.vertices).map({ case (k, (r, v)) => (r, v, k) }).sortBy(50 - _._1)report.take(50).foreach(println)Full example code: https://github.com/SANSA-Stack/SANSA-Examples/blob/master/sansa-examples-spark/src/main/scala/net/sansa_stack/examples/spark/rdf/PageRank.scala
Back to top
OWL Processing
1. How can I load an OWL file in format XYZ?
-
- Functional syntax
RDD
1FunctionalSyntaxOWLAxiomsRDDBuilder.build(sc, "path/to/functional/syntax/file.owl")Dataset
1FunctionalSyntaxOWLAxiomsDatasetBuilder.build(spark, "path/to/functional/syntax/file.owl")- Manchester syntax
RDD
1ManchesterSyntaxOWLAxiomsRDDBuilder.build(sc, "path/to/manchester/syntax/file.owl")Dataset
1ManchesterSyntaxOWLAxiomsDatasetBuilder.build(sc, "path/to/manchester/syntax/file.owl")Full example code: https://github.com/SANSA-Stack/SANSA-Examples/tree/master/sansa-examples-spark/src/main/scala/net/sansa_stack/examples/spark/owl
-
- Functional syntax
1FunctionalSyntaxOWLAxiomsDataSetBuilder.build(env, "path/to/functional/syntax/file.owl")- Manchester syntax
1ManchesterSyntaxOWLAxiomsDataSetBuilder.build(env, "path/to/manchester/syntax/file.owl")Full example code: https://github.com/SANSA-Stack/SANSA-Examples/blob/master/sansa-examples-flink/src/main/scala/net/sansa_stack/examples/flink/owl/OWLReaderDataSet.scala
2. How can I retrieve all axioms of type XYZ?
-
- E.g. OWLSubClassOfAxiom:
1234rdd.filter(axiom => axiom match {case a: OWLSubClassOfAxiom => truecase _ => false})
3. How can I print loaded OWL axioms?
-
1data.collect().foreach(println)
-
1dataSet.print()
Back to top
SPARQL Queries
1. How does SANSA perform distributed RDF querying?
SANSA uses vertical partitioning (VP) approach and is designed to support extensible partitioning of RDF data. Instead of dealing with a single three-column table (s, p, o), data is partitioned into multiple tables based on the used RDF predicates, RDF term types and literal datatypes. The first column of these tables is always a string representing the subject. The second column always represents the literal value as a Scala/Java datatype. Tables for storing literals with language tags have an additional third string column for the language tag.
-
The method for partitioning a RDD[Triple] is located in RdfPartitionUtilsSpark. It uses an RdfPartitioner which maps a Triple to a single RdfPartition instance.
- RdfPartition, as the name suggests, represents a partition of the RDF data and defines two methods:
- matches(Triple): Boolean: This method is used to test whether a triple fits into a partition.
- Layout => TripleLayout: This method returns the TripleLayout associated with the partition, as explained below.
- Furthermore,RdfPartitions are expected to be serializable, and to define equals and hash code.
- TripleLayout instances are used to obtain framework-agnostic compact tabular representations of triples according to a partition. For this purpose it defines the two methods:
- fromTriple(triple:Triple): Product: This method must, for a given triple, return its representation as a Product(this is the super class of all scalaTuples)
- schema:Type: This method must return the exact scala type of the objects returned by fromTriple, such as typeOf[Tuple2[String,Double]]. Hence, layouts are expected to only yield instances of one specific type.
See the available layouts for details.
- RdfPartition, as the name suggests, represents a partition of the RDF data and defines two methods:
2. How can I query an RDF file using SPARQL?
-
123456val graphRdd = NTripleReader.load(spark, URI.create(input))val partitions = RdfPartitionUtilsSpark.partitionGraph(graphRdd)val rewriter = SparqlifyUtils3.createSparqlSqlRewriter(spark, partitions)val qef = new QueryExecutionFactorySparqlifySpark(spark, rewriter)
Full example code: https://github.com/SANSA-Stack/SANSA-Examples/blob/master/sansa-examples-spark/src/main/scala/net/sansa_stack/examples/spark/query/Sparklify.scala
3. How can I start an HTTP SPARQL server?
-
12val server = FactoryBeanSparqlServer.newInstance.setSparqlServiceFactory(qef).createserver.join()
Back to top
Inference
1. How does the SANSA inference module work?
The inference layer supports rule-based reasoning, i.e. given a set of rules it computes all possible inferences on the given dataset. Technically, forward-chaining [1] is applied, i.e. it starts with the available data and uses inference rules to extract more data. This is sometimes also referred to as “materialization”.
Currently, three fixed rulesets are supported, namely RDFS, OWL-Horst, and OWL-EL. Later versions will contain a generic rule-based reasoner such that a user can define it’s own set of rules which will be used to materialize the given dataset.
[1] https://en.wikipedia.org/wiki/Forward_chaining
2. How can I use the inference layer?
The easiest way is to use the RDFGraphMaterializer:
1234567891011121314151617// load triples from diskval graph = RDFGraphLoader.loadFromDisk(input, spark, parallelism)// create reasonerval reasoner = profile match {case TRANSITIVE => new TransitiveReasoner(spark.sparkContext, parallelism)case RDFS => new ForwardRuleReasonerRDFS(spark.sparkContext, parallelism)case RDFS_SIMPLE =>var r = new ForwardRuleReasonerRDFS(spark.sparkContext, parallelism) //.level.+(RDFSLevel.SIMPLE)r.level = RDFSLevel.SIMPLErcase OWL_HORST => new ForwardRuleReasonerOWLHorst(spark.sparkContext)}// compute inferred graphval inferredGraph = reasoner.apply(graph)// write triples to diskRDFGraphWriter.writeGraphToFile(inferredGraph, output.getAbsolutePath, writeToSingleFile, sortedOutput)
Full example code: https://github.com/SANSA-Stack/SANSA-Examples/blob/master/sansa-examples-spark/src/main/scala/net/sansa_stack/examples/spark/inference/RDFGraphInference.scala-
1234567891011121314151617// load triples from diskval graph = RDFGraphLoader.loadFromDisk(input, env)// create reasonerval reasoner = profile match {case RDFS => new ForwardRuleReasonerRDFS(env)case RDFS_SIMPLE => {val r = new ForwardRuleReasonerRDFS(env)r.level = RDFSLevel.SIMPLEr}case OWL_HORST => new ForwardRuleReasonerOWLHorst(env)}// compute inferred graphval inferredGraph = reasoner.apply(graph)// write triples to diskRDFGraphWriter.writeToDisk(inferredGraph, output, writeToSingleFile, sortedOutput)
Full example code: https://github.com/SANSA-Stack/SANSA-Examples/blob/master/sansa-examples-flink/src/main/scala/net/sansa_stack/examples/flink/inference/RDFGraphInference.scala
Back to top
Machine Learning
1. How can I use SANSA for clustering on RDF graph?
SANSA contains the implementation of a partitioning algorithm for RDF graphs given as NTriples. The algorithm uses the structure of the underlying undirected graph to partition the nodes into different clusters. SANSA’s clustering procedure follows a standard algorithm for partitioning undirected graphs aimed to maximize a modularity function, which was first introduced by Newman.
You will need your RDF graph in the form of a text file, with each line containing exactly one triple of the graph. Then you specify the number of iterations and supply a file path where you want your resulting clusters to be saved to.
-
1234567import net.sansa_stack.ml.spark.clustering.RDFByModularityClusteringval numIterations = 100val input ="path_to_your_RDFgraph.txt"val output ="path_name_for_clusters.txt"RDFByModularityClustering(spark.sparkContext, numIterations, input, output)
Full example code: https://github.com/SANSA-Stack/SANSA-Examples/blob/master/sansa-examples-spark/src/main/scala/net/sansa_stack/examples/spark/ml/clustering/RDFByModularityClustering.scala
-
123456789import net.sansa_stack.ml.flink.clustering.RDFByModularityClusteringval numIterations = 100val input ="path_to_your_RDFgraph.txt"val output ="path_name_for_clusters.txt"val env = ExecutionEnvironment.getExecutionEnvironmentRDFByModularityClustering(env, numIterations, graphFile, outputFile)
Full example code: https://github.com/SANSA-Stack/SANSA-Examples/blob/master/sansa-examples-flink/src/main/scala/net/sansa_stack/examples/flink/ml/clustering/RDFByModularityClustering.scala
2. How can I use SANSA for mining rules?
Rule mining for knowledge bases is used to look for new facts, or such rules can be used to identify errors in the knowledge bases. These rules can be used for reasoning, and the rules that define regularities in the data can be used to understand the data better.
SANSA uses AMIE+ algorithm to mine association rules or correlations in the RDF dataset. These rules have the form r(x,y) <= B1 & B2 & … Bn while r(x,y) is the head and B the body, a conjunction of atoms of the rule. The process starts with rules with only one atom, which are then refined to add more atoms with fresh or previously used variables. The rules is accepted as output rule, if its support is above a support threshold.
-
Within spark, the support of a rule is calculated using DataFrames. For the rules with two atoms, the predicates of head and body are filtered against a dataframe, which contains all the instantiated atoms with a particular predicate. Different dataframes are then joined and only the rows with correct variables are kept. For greater sizes, new atoms are joined with the previous dataframes (previously refined rules), which are stored in the parquet format with rules as name for corresponding folders.
12345678910111213141516171819202122232425262728293031323334import net.sansa_stack.ml.spark.mining.amieSpark.KBObject.KBimport net.sansa_stack.ml.spark.mining.amieSpark.{ RDFGraphLoader, DfLoader }import net.sansa_stack.ml.spark.mining.amieSpark.MineRules.Algorithmimport net.sansa_stack.ml.spark.mining.amieSpark.MineRules.Algorithmval know = new KB()know.sethdfsPath(hdfsPath)know.setKbSrc(input)know.setKbGraph(RDFGraphLoader.loadFromFile(know.getKbSrc(), spark.sparkContext, 2))know.setDFTable(DfLoader.loadFromFileDF(know.getKbSrc, spark.sparkContext, sparkSession.sqlContext, 2))val algo = new Algorithm(know, 0.01, 3, 0.1, hdfsPath)//var erg = algo.ruleMining(spark.sparkContext, spark.sqlContext)//println(erg)var output = algo.ruleMining(spark.sparkContext, spark.sqlContext)var outString = output.map { x =>var rdfTrp = x.getRule()var temp = ""for (i <- 0 to rdfTrp.length - 1) {if (i == 0) {temp = rdfTrp(i) + " <= "} else {temp += rdfTrp(i) + " \u2227 "}}temp = temp.stripSuffix(" \u2227 ")temp}.toSeqvar rddOut = spark.sparkContext.parallelize(outString)rddOut.saveAsTextFile(outputPath + "/testOut")Full example code: https://github.com/SANSA-Stack/SANSA-Examples/blob/master/sansa-examples-spark/src/main/scala/net/sansa_stack/examples/spark/ml/mining/MineRules.scala
3. How can I use SANSA for Knowledge Graph Embedding Models?
Currently there are two Knowledge Graph Embedding (KGE) models are implemented: TransE [1] and DistMult (Bilinear-Diag) [2].
The following code snippets show you how you can load your dataset and apply cross validation techniques supported on SANSA KGE.
-
12345678910111213141516171819// dataset to be loadedval input = "fb15k.txt"// technique used to split the dataval technique = "holdout"val k = 5val data = new Triples(input, "\t", false, false, spark)// converting the original data to indexDataval indexedData = new ByIndex(data.triples, spark)val numericData = indexedData.numeric()val (train, test) = technique match {case "holdout" => new Holdout(numericData, 0.6f).crossValidation()case "bootstrapping" => new Bootstrapping(numericData).crossValidation()case "kFold" => new kFold(numericData, k, spark).crossValidation()case _ =>throw new RuntimeException("'" + technique + "' - Not supported, yet.")}
[1] Bordes et. al., Translating Embeddings for Modeling Multi-relational Data
[2] Yang et. al., Embedding Entities and Relations for Leaning and Inference in Knowledge Graphs