Large amounts of data are being published openly to Linked Data by different data providers. A multitude of applications such as semantic search, query answering, and machine reading depend on these large-scale RDF datasets. SPARQL is W3C standard for querying the data stored as Resource Description Framework (RDF). The SPARQL queries are represented using triple-patterns, and are tailored to search for these patterns in RDF triples. Most of the existing SPARQL evaluators provide centralized, DBMS inspired solutions consuming high resources and offering limited flexibility.
In order to deal with the increasing RDF data, it is important to develop scalable and efficient solutions for distributed SPARQl query evaluators. We introduce DISE — an open source implementation of distributed in-memory SPARQL engine that can scale out to a cluster of machines. DISE represents an RDF graph as a three way distributed tensor for querying large-scale RDF datasets. This distributed tensor representation offers opportunities for novel distributed applications.
DISE relies on translating SPARQL queries into Spark tensor operations by exploiting the information about the query complexity (degree of freedom).
Architecture
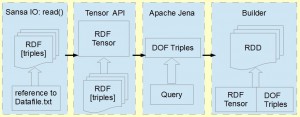
Fig. 1. Overview of DISE architecture.
We model and store RDF graphs based on the basic building block of the Spark framework, RDDs.
The work done here (available under Apache License 2.0) has been integrated into SANSA, an open source data flow processing engine for scalable processing of large-scale RDF datasets. SANSA uses Spark and Flink which offer fault-tolerant, highly available and scalable approaches to process massive sized datasets efficiently. SANSA provides the facilities for semantic data representation, querying, inference, and analytics at scale.