The SANSA team is excited to announce our collaboration with Alethio (a ConsenSys formation). SANSA is the major distributed, open source solution for RDF querying, reasoning and machine learning. Alethio is building an Ethereum analytics platform that strives to provide transparency over what’s happening on the Ethereum p2p network, the transaction pool and the blockchain and provide “blockchain archeology”. Their 5 billion triple data set contains large scale blockchain transaction data modelled as RDF according to the structure of the Ethereum ontology. EthOn – The Ethereum Ontology – is a formalization of concepts/entities and relations of the Ethereum ecosystem represented in RDF and OWL format. It describes all Ethereum terms including blocks, transactions, contracts, nonces etc. as well as their relationships. Its main goal is to serve as a data model and learning resource for understanding Ethereum.
Alethio is interested in using SANSA as a scalable processing engine for their large-scale batch and stream processing tasks, such as querying the data in real time via SPARQL and performing related analytics on a wide range of subjects (e.g. asset turnover for sets of accounts, attack pattern detection or Opcode usage statistics). At the same time, SANSA is interested in further industrial pilot applications for testing the scalability on larger datasets, mature its code base and gain experience on running the stack on production clusters. Specifically, the initial goal of Alethio was to load a 2TB EthOn dataset containing more than 5 billion triples and then performing several analytic queries on it with up to three inner joins. The queries are used to characterize movement between groups of ethereum accounts (e.g. exchanges or investors in ICOs) and aggregate their in and out value flow over the history of the Ethereum blockchain. The experiments were successfully run by Alethio on a cluster with up to 100 worker nodes and 400 cores that have a total of over 3TB of memory available.
“I am excited to see that SANSA works and scales well to our data. Now, we want to experiment with more complex queries and tune the Spark parameters to gain the optimal performance for our dataset” said Johannes Pfeffer, co-founder of Alethio. “I am glad that Alethio managed to run their workload and to see how well our methods scale to a 5 billion triple dataset”, added Gezim Sejdiu, PhD student at the Smart Data Analytics Group and SANSA core developer.
Parts of the SANSA team, including its leader Prof. Jens Lehmann as well as Dr. Hajira Jabeen, Dr. Damien Graux and Gezim Sejdiu, will now continue the collaboration together with the data science team of Alethio after those successful experiments. Beyond the above initial tests, we are jointly discussing possibilities for efficient stream processing in SANSA, further tuning of aggregate queries as well as suitable Apache Spark parameters for efficient processing of the data. In the future, we want to join hands to optimize the performance of loading the data (e.g. reducing the disk footprint of datasets using compression techniques allowing then more efficient SPARQL evaluation), handling the streaming data, querying, and analytics in real time.
The SANSA team is happily looking forward to further interesting scientific research as well as industrial adaptation.
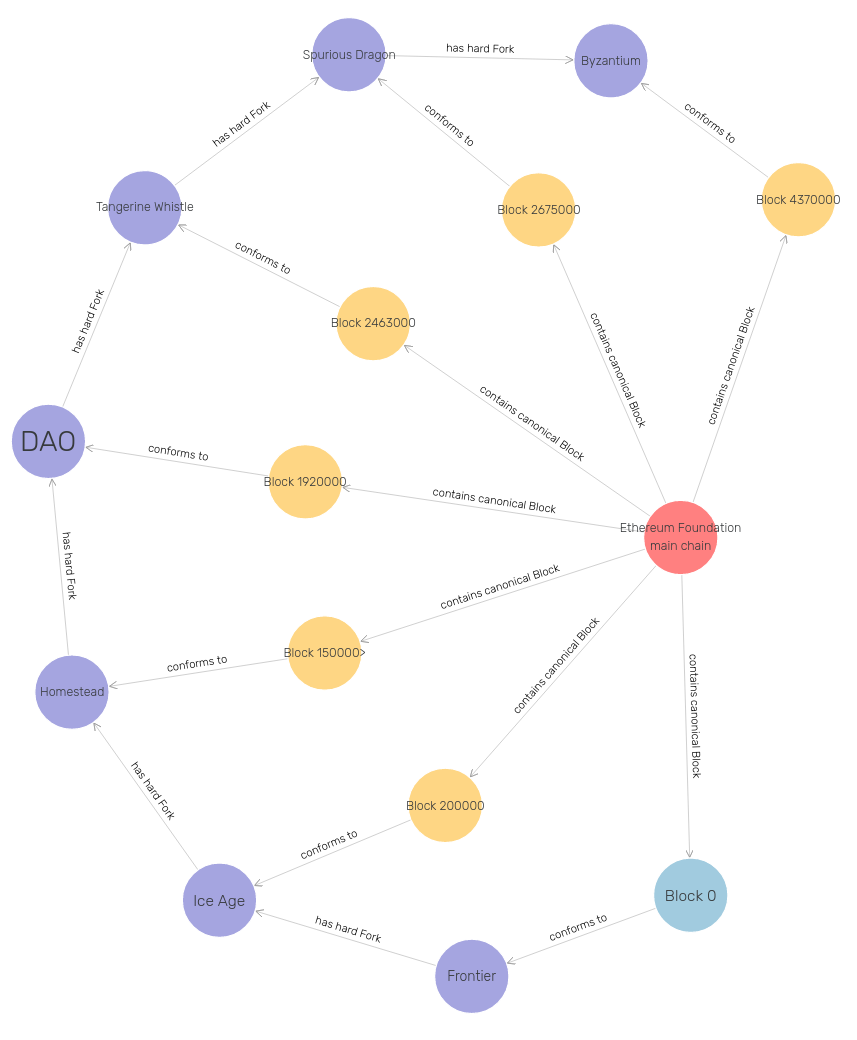
Core model of the fork history of the Ethereum Blockchain modeled in EthOn