Large amounts of data are being published openly to Linked Data by different data providers. A multitude of applications such as semantic search, query answering, and machine reading depend on these large-scale RDF datasets. The quality of underlying RDF data plays a vital role in these data consuming applications. Measuring the quality of linked data spans a number of dimensions including but not limited to: accessibility, interlinking, performance, syntactic validity or completeness. Each of these dimensions can be expressed through one or more quality metrics. Considering that each quality metric tries to capture a particular aspect of the underlying data, numerous metrics are usually provided against given data that may or may not be executed simultaneously.
On the other hand, the limited number of existing techniques of quality assessment for RDF datasets are not adequate to assess data quality at large-scale and these approaches mostly fail to capture the increasing volume of big data. To date, a limited number of solutions have been conceived to offer quality assessment of RDF datasets. But, these methods can either be used on a small portion of large datasets or narrow down to specific problems e.g., syntactic accuracy of literal values, or accessibility of resources. In general, these existing efforts show severe deficiencies in terms of performance when data grows beyond the capabilities of a single machine. This limits the applicability of existing solutions to medium-sized datasets only, in turn, paralyzing the role of applications in embracing the increasing volumes of the available datasets.
To deal with big data, tools like Apache Spark have recently gained a lot of interest. Apache Spark provides scalability, resilience, and efficiency for dealing with large-scale data. Spark uses the concepts of Resilient Distributed Datasets (RDDs) and performs operations like transformations and actions on this data in order to effectively deal with large-scale data. To handle large-scale RDF data, it is important to develop flexible and extensible methods that can assess the quality of data at scale. At the same time, due to the broadness and variety of quality assessment domain and resulting metrics, there is a strong need to provide a pattern to characterize the quality assessment of RDF data in terms of scalability and applicability to big data.
We borrow the concepts of data transformation and action from Spark and present a pattern for designing quality assessment metrics over large RDF datasets, which is inspired by design patterns. Akin to the design pattern, where each pattern is like a blueprint that can be customized to solve a particular design problem, the introduced concept of Quality Assessment Pattern (QAP) represents a generalized blueprint of quality assessment metrics in a scalable manner. In this way, the quality metrics designed following QAP can exhibit the ability to achieve scalability to large-scale data and work in a distributed manner.
In addition, we also provide an open source implementation and assessment of these quality metrics in Apache Spark following the proposed QAP.
We introduce DistQualityAssessment — a distributed (open source) implementation of quality metrics using Apache Spark which scales out to clusters of multiple machines.
Architecture
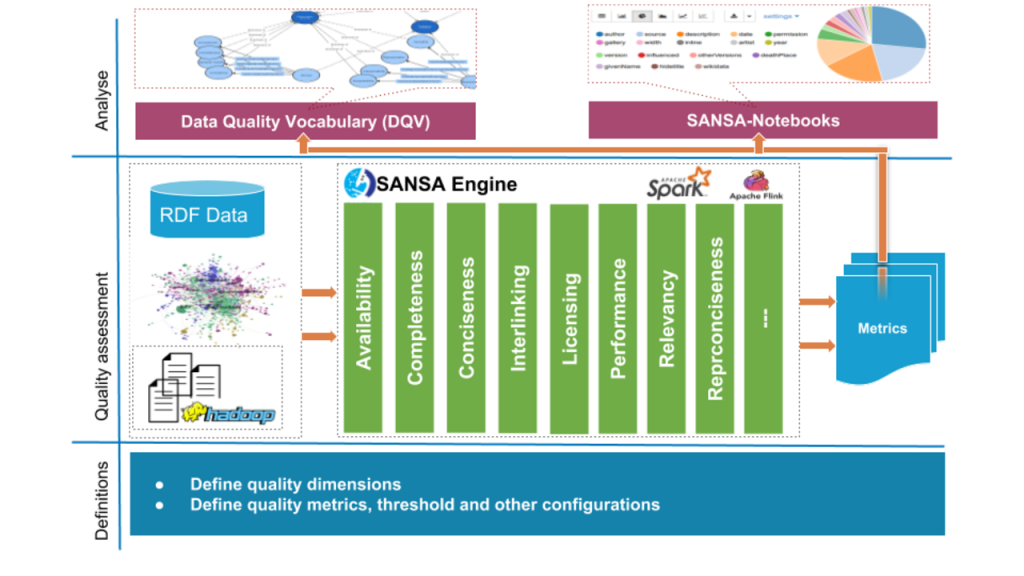
Fig. 1. Overview of DistQualityAssessment abstract architecture.
We model and store RDF graphs based on the basic building block of the Spark framework, RDDs. The computation of the set of quality metrics is performed using Spark as depicted in the Fig.1. It consist of four steps:
- Defining quality metrics parameters — the metric definitions are kept in a dedicated file which contains most of the configurations needed for the system to evaluate quality metrics and gather result sets.
- Retrieving the RDF data — RDF data first needs to be loaded into a large-scale storage that Spark can efficiently read from. We use Hadoop Distributed File-System(HDFS).
- Parsing and mapping RDF into the main dataset — first create a distributed dataset called \emph{main dataset} that represent the HDFS file as a collection of triples. At Spark execution, this dataset is parsed and loaded into an RDD of triples having the following format Triple<(s,p,o)>.
- Quality metric evaluation — considering every quality metric, Spark generates an execution plan, which is composed of one or more transformations and actions.
Furthermore, we also provide a Docker image of the system integrated within the BDE platform – an open source Big Data processing platform allowing users to install numerous big data processing tools and frameworks and create working data flow applications.
The work done here (available under Apache License 2.0) has been integrated into SANSA, an open source data flow processing engine for scalable processing of large-scale RDF datasets. SANSA uses Spark and Flink which offer fault-tolerant, highly available and scalable approaches to process massive sized datasets efficiently. SANSA provides the facilities for semantic data representation, querying, inference, and analytics at scale.
How to use it
The component is part of the SANSA Stack, therefore it comes as implicit of the SANSA. Below, we give some examples of the quality metrics which can be called using the SANSA API.
-
In this example, we use SANSA readers to build a dataset of RDD[Triple] called triples and then compute some of the quality metrics.
1234567891011121314151617181920import net.sansa_stack.rdf.spark.io._import net.sansa_stack.rdf.spark.qualityassessment._import org.apache.jena.riot.Langval input = "hdfs://..."val lang = Lang.NTRIPLESval triples = spark.rdf(lang)(input)// compute quality assessmentval completeness_schema = triples.assessSchemaCompleteness()val completeness_interlinking = triples.assessInterlinkingCompleteness()val completeness_property = triples.assessPropertyCompleteness()val syntacticvalidity_XSDDatatypeCompatibleLiterals = triples.assessXSDDatatypeCompatibleLiterals()val availability_DereferenceableUris = triples.assessDereferenceableUris()val relevancy_CoverageDetail = triples.assessCoverageDetail()val understandability_LabeledResources = triples.assessLabeledResources()Full example code: https://github.com/SANSA-Stack/SANSA-Examples/blob/develop/sansa-examples-spark/src/main/scala/net/sansa_stack/examples/spark/rdf/RDFQualityAssessment.scala
The DistQualityAssessment has been piped into the SANSA-Notebooks as well, therefore users can use it without many configurations beforehand. SANSA-Notebooks is developer-friendly access to SANSA, which provide a web-editor interface for using the SANSA functionality.
Full example code: https://github.com/SANSA-Stack/SANSA-Notebooks/wiki/RDF-notebook#rdf-quality-assessment-example