Introducing Scalable Semantic Analytics Stack (SANSA Stack)
In order to deal with the massive data being produced at scale, the existing big data frameworks like Spark and Flink offer fault tolerant, high available and scalable approaches to process massive sized data sets efficiently. These frameworks have matured over the years and offer a proven and reliable method for the processing of large scale unstructured data.
We have decided to explore the use of these two prominent frameworks for RDF data processing. We are developing a library named Semantic Analytics Stack SANSA, that can process massive RDF data at scale and perform learning and prediction for the data. This would be in addition to answering queries from the data. The following section describes working of SANSA and its key features grouped by each layer of the stack. Although we aim to support both Spark and Flink. However, our main focus is Spark at the moment, therefore, the following discussion would mainly be in the context of different features offered by Spark. Figure 1 depicts the working of the SANSA stack, where RDF layer offers a basic API to read and write native RDF data. On top there are Querying and Inference layer. Then, we would also offer a machine learning library that could perform several machine learning tasks out of the box on linked RDF data.
Architecture
The core idea of SANSA-Stack is drawn from the valuable lessons that we have learned through the experience of big data tools and technologies and a lot of background knowledge over semantic web of data.
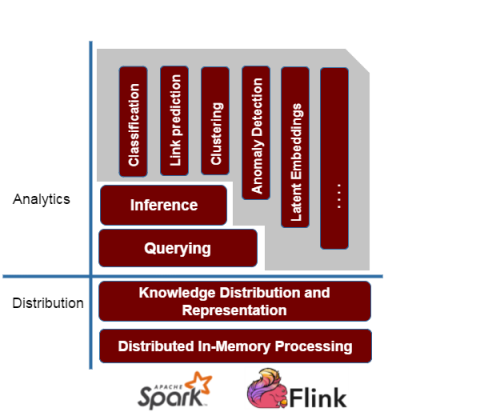
Figure 1. SANSA-Stack architecture
Read Write layer
The lowest layer on top of existing frameworks e.g. Spark or Flink is the read/write layer. This layer essentially provides the facility to read / write native RDF data from HDFS or local drive and represent it in the native distributed data structures of Spark. In addition, we also require a dedicated serialization mechanism for faster I/O.
We also decided to support the Jena interface API to perform the relevant tasks. This is particularly aimed for usability, as most of the users are already familiar with the interface and it would require lesser time in getting used the new distributed SANSA stack.
Querying Layer
Querying an RDF graph is a major source of information extraction and searching from the underlying linked data. This is essential to browse, search and explore the structured information available in a fast and user friendly manner.
SPARQL, also known as RDF query language, is the W3C standard for querying RDF graphs. SPARQL is very expressive and allows to extract complex relationships using intelligent and comprehensive SPARQL queries. SPARQL takes the description in the form of a query, and returns that information, in the form of a set of bindings or an RDF graph.
In order to efficiently answer runtime queries for large RDF data, we are exploring the three representation formats of SPARK namely Resilient Distributed Datasets (RDD), Spark Data Frames, and Spark GraphX which is graph parallel computation.
Our aim is to have cross representational transformations for efficient query answering. Our conclusion so far is that the Spark GraphX is not very efficient due to complex querying related to graph structure. On the other hand, an RDD based representation is efficient for queries like filters or applying a User Defined Function (UDF) on specific resources. At the same time, we are exploring use of SparkSQL Data Frames and compare the performance to analyse which representation suits particular type of query answering.
Inference Layer
Both RDFS and OWL contain schema information, in addition to links between different resources. This additional information and rules allows to perform reasoning on the knowledge bases to infer new knowledge and expand existing knowledge base.
This layer is relevant to more complex representations like ontologies mentioned above. An ontology provides shared vocabulary and inference rules to represent domain specific knowledge. Ontologies are used for the purpose of enabling machines to automatically understand information and infer new knowledge. Therefore, useful ontologies are adapted to represent context for ubiquitous computing and manage knowledge service systems. To efficiently build ontology based knowledge service systems, management and reasoning for large scale ontology is desired. One can perform sound and complete reasoning on small ontologies, however it could become very ineffective for very large scale knowledge bases.
Therefore, we have want to exploit Spark and Flink for inferencing from large ontologies. The core of the inference process is to continuously apply the schema related rule on the input data to infer new facts. This process is helpful for deriving new facts from the knowledge base, detect inconsistencies from the KB, extract new rules to help in reasoning, and Rule describing general regularity can can help us understanding the data better. We have developed a prototype inference engine and are working towards its refinement and performance enhancement.
Machine Learning Layer
In addition to above mentioned tasks, one of the very important task for any data is to perform machine learning or analytics to gain insights of the data for relevant trends, predictions or detection of anomalies.
There exist a wide range of machine learning algorithms for the structured data. However that challenging task would be to distribute the data and to devise distributed versions of these algorithms to fully exploit the underlying frameworks. We are exploring different algorithms namely, tensor factorization, association rule mining, decision trees and clustering on structured data. The aim would be to provide out of the box algorithms to work with the structured data and a distributed, fault tolerant and resilient fashion.
Sansa is a research-work in progress, where we are exploring existing efforts towards Big RDF processing frameworks, and aim to build a generic stack, which can work with large sized Linked Data, offering fast performance in addition to working as an out of the box framework for scalable and distributed semantic data analysis.